CloudFormationテンプレートを書いてスタックを作成する方法初級
CloudFormationのテンプレートを作成するとき、 はじめての人は何をすれば良いのかがよくわからない気持ちになるものです、たぶん。
なのでテンプレートについての簡単な解説を。。。

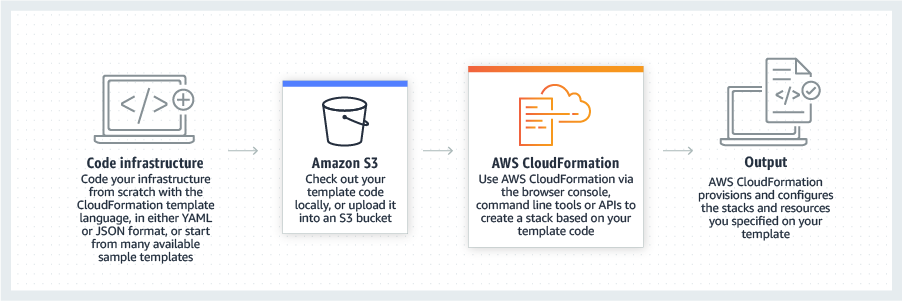
CloudFormationについて
CloudFormationとは、AWSのリソースを簡単に構築することができる機能のことです。
YAML/JSONファイルにリソースの設定を書き込んで、AWSコンソールのCloudFormationでファイルをアップロードすると、 設定したリソースが作成されていきます。 もちろんCLIでもアップロードができます。
これら一つのYAML/JSONファイルに設定された一連のリソース群のことをスタックと呼びます。 アップロードが完了すると、AWSコンソール上のCloudFormationではスタックの作成が始まります。
CloudFormationのテンプレートは単純にリソースを構築するだけではなく、 プロジェクトで利用されているAWSリソースの構成図としても役立ちます。
AWSコンソール上では把握しづらいリソース間の関係性も、 テンプレートファイル上で概要をつかむことができます(読める知識があれば)。
簡単にお試しできそうな記事がありました↓ 【CloudFormation入門】5分と6行で始めるAWS CloudFormationテンプレートによるインフラ構築
CloudFormationの基本的なパラメーター
CloudFormationを始めるにあたって理解しておいた方が良いパラメーターは以下の3つです。
- Parameters
- Outputs
- Resources
まず、テンプレートの冒頭はこんな感じになると思います。
AWSTemplateFormatVersion: '2010-09-09' Description: Your project name # 別に必須ではない
上に挙げているパラメーターはこのDescription下に付け足して書いていきます。
ちなみにこのエントリーではYAMLでテンプレートを書いています。
Resources
ResourcesにはAWSリソースを定義していきます。 それぞれのリソースは機能役割が異なるので、各々の設定方法が存在します。
リソースの定義は想定している構成でどのリソースを使うべきかを判断し上で、 以下のリストから探して試していくと良いです。
設定方法
全てのリソースについて説明することは不可能なので、 ここにはVPCとInternetGatewayの組み合わせをサンプルで記載します。
Resources: MyVPC: Type: AWS::EC2::VPC Properties: CidrBlock: "10.0.0.0/16" Tags: - Key: "Name" Value: "MyVPC" MyInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: "Name" Value: "MyInternetGateway" AttachGatewayToVPC: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !Ref MyVPC InternetGatewayId: !Ref MyIGW
IPv4 CIDR ブロックを指定してVPCを作成し、インターネットゲートウェイ(IGW)を関連づけています。
VPCとIGWの参照にはRef組み込み関数(YAMLの短縮記法)を使います。
VPCとIGWを関連づけるためにはAWS::EC2::VPCGatewayAttachmentを利用します。
周知の通り、VPC内からインターネットへアクセスするにはIGWが必須です。
上記のサンプルでは基本的なVPCを設定しているだけです。
ここからサブネットやルートテーブル、EC2インスタンスをスタックに追加してあげると、 インスタンス内で開発を行えるところまでをCloudFormationで構築することができるようになります。
下記のリソースを設定すればできます。
AWS::EC2::Subnet サブネットの作成 AWS::EC2::Instance EC2インスタンスの作成 AWS::EC2::RouteTable ルートテーブルの作成 AWS::EC2::SubnetRouteTableAssociation サブネットとルートテーブルの関連付け AWS::EC2::Route ルートテーブルとIGWの関連付け
Parameters
Parametersでは同じテンプレート内で利用する値を設定することができます。
設定方法
と言ってもはじめての人にはこの言葉では理解しづらいと思うので具体的に設定を見てみましょう。
Parameters: S3BucketNameParameter: Type: String # パラメーターの型 Default: 'Megalovania' # 初期値 AllowedPattern: ^[a-zA-Z0-9]*$ # 正規表現に合致するものを許容します。 AllowedValues: # enumのようにこの中の値を許容します。 - 'Megalovania' - 'TheManWithTheMachineGun' - 'BlueEyesWhiteDragon'
DefaultではCloudFormationでのスタック作成時に設定しなかった場合の初期値を設定します(AWSコンソール上からCFnスタック作成をするときにGUIで設定できる、けどしなかった場合の初期値)。
AllowedPatternとAllowedValuesではその初期値やあとで設定し直した時の値のルールを設定できます。
正規表現や想定されている値が数個しかない場合はこれらを使ってみると良いと思います。
参照方法
参照はResourcesおよびこのあと登場するOutputsで行えます。
組み込み関数のRefを使って参照します。
# in case of Resources Resources: MyBucket: Type: AWS::S3::Bucket Properties: BucketName: !Ref S3BucketNameParameter # 'Megalovania' # in case of Outputs Outputs: ExportedBucket: Description: "MyBucket" Value: !Ref MyBucket Export: Name: "ExportedBucket"
Outputs
Outputsを使うと、同一リージョン内に作成された他のスタックで参照可能な値を設定したり、CloudFormationコンソール上にリリース担当者に参照してほしいリソースを表示したりすることができます。
設定方法
# スタックA AWSTemplateFormatVersion: "2010-09-09" Resources: SampleVPC: Type: AWS::EC2::VPC Properties: CidrBlock: "10.0.0.0/16" Tags: - Key: "Name" Value: "SampleVPC" Outputs: ExportedVPC: Description: "SampleVPC" # 説明 Value: !Ref SampleVPC # エクスポートする値 Export: Name: "ExportedSampleVPC" # インポートするときに参照する名前
参照方法
次にエクスポートした値を参照しながら別のスタックを作成します。 上記ではVPCをエクスポートしたので、そのVPCに対してIGWをアタッチしてみます。
参照時にはFn::ImportValue組み込みを利用します。
YAMLでは組み込み関数の短縮記法が使えるので、ここでは!ImportValueとしています。
# スタックB AWSTemplateFormatVersion: "2010-09-09" Resources: MyInternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: "Name" Value: "MyInternetGateway" AttachGateway: Type: AWS::EC2::VPCGatewayAttachment Properties: VpcId: !ImportValue ExportedSampleVPC # ExportのNameで指定した名前から値を参照します。 InternetGatewayId: !Ref MyInternetGateway
こうするとスタックAで作成されたVPCにスタックBで作成されたIGWが関連付きます。 スタック間を超えて参照したいリソースがあれば便利に使うことができます。
また、作成したスタックのOutputsはAWSコンソール上でも参照することができます。

例えば、
「ReactクライアントのビルドファイルをアップロードS3バケットはどれだったっけ?」
というようなときに、このCloudFormationコンソールのOutputsからバケット名が参照できればわざわざドキュメントにまとめる必要も無くなります。 せいぜい、「コンソールの出力を参照してください」と指示するくらいでしょう。
特に複雑に肥大したスタックなどには主要なものはOutputsにまとめておくと良いと思います。
テンプレートのアップロードとスタック作成
テンプレートが書けてもスタックの作り方がわからなければ意味がありません。 ただテンプレートを流し込むだけなので全く難しいことなどはありませんが。。。
一応ざっくりと手順に触れておきます。
1. CloudFormationコンソールへ入る
AWSコンソールでCloudFormationを開くとスタック一覧画面の上の方に「スタック作成」(Create stack)ボタンを見つけられると思います。

ドロップダウンになっているので「新しいスタック」(With new resources)を選択します。
2. テンプレートファイルを選択

スタック作成画面では「既存のテンプレート」(Template is ready)から「テンプレートをアップロード」(Upload a template file)を選択し、テンプレートファイルYAML/JSONを選択して「次へ」(Next)を押します。
3. スタック名を決める
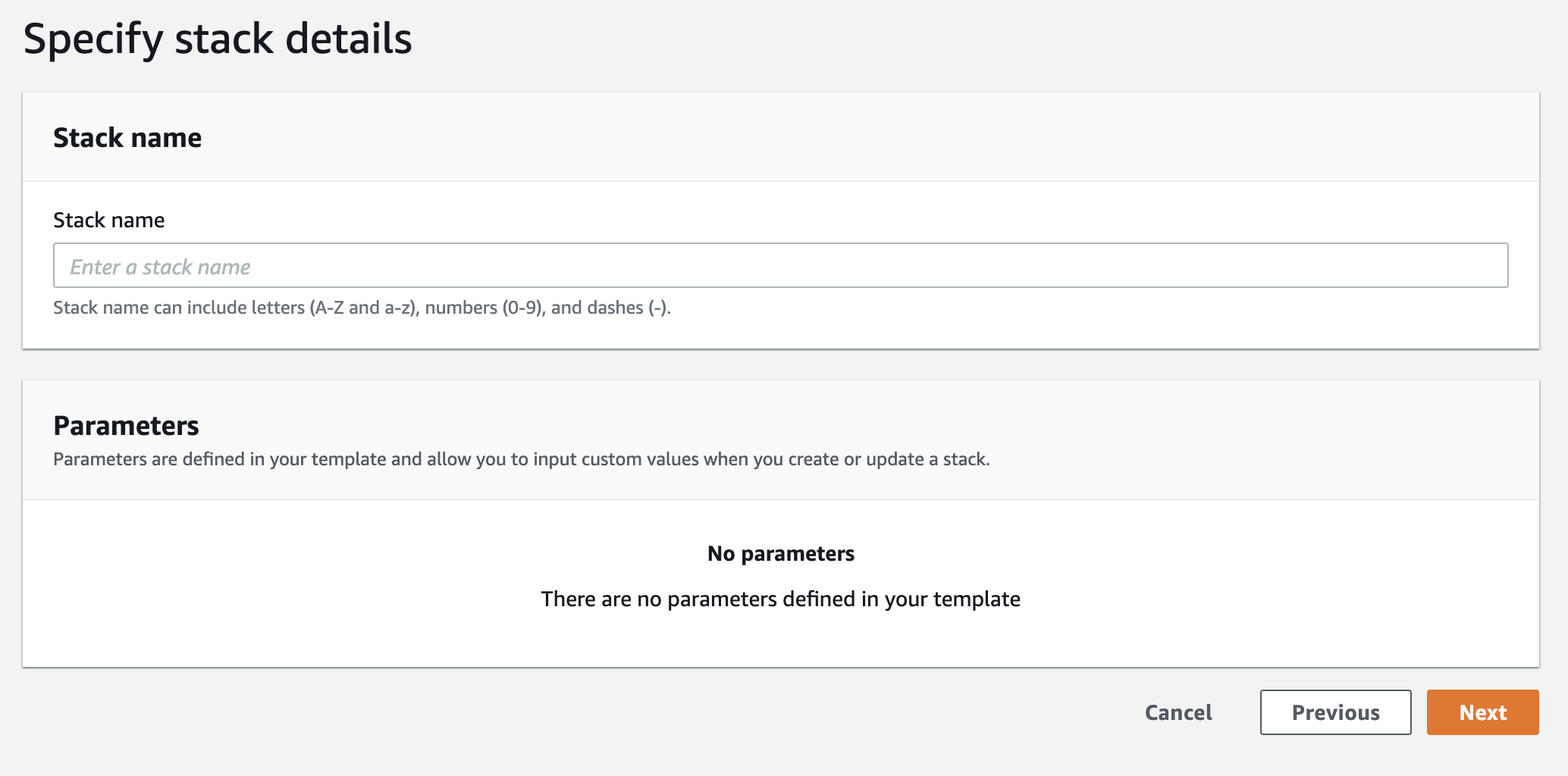
スタック名を記入して「次へ」(Next)を押します。
4. 詳細設定(やりたい人だけ)
次のページの詳細設定等は省いて「次へ」(Next)を押します。 設定したいことがあればします。
5. 確認とスタックの作成実行
確認画面が表示されるので、確認ができたら下部の「スタック作成」(Create stack)を押します。
するとスタックの作成が始まってステータスがCREATE_IN_PROGRESSとなるのがわかると思います。
設定したリソースの量にもよりますが少しすればスタックがCREATE_COMPLETEになります。
問題があればエラーも出ますが、基本的には以上がスタック作成の基本的な流れです。 コンソール上でリソースが作成されているのを確認できると思います。
おわり
以上の基本的なパラメーターについてとりあえず触れましたが、 CloudFormationを理解するには組み込み関数についても知る必要があります。
これは上でも触れた!Refとか!ImportValueみたいなやつのことです。
組み込み関数には条件関数というものもあって、より柔軟にスタックテンプレートを作成することができるようになります。
今の職場では複数の環境(お客様が別々で要望も別々なので環境を分けている)がそれぞれの環境差異を持っているので各スタックテンプレートで組み立てているのですが、 そうは言っても類似した部分の共通簡略化は行いたくなるのでテンプレートの部分分岐をしたりします。 こういったときに条件関数が使えるので知っておいて損はないと思います。
まあ、CloudFormationを便利に使ってみてください〜
SAM CLIでサーバレスアプリケーションを作ってみる【API Gateway + Lambda + DynamoDB】
SAM CLIでAPI Gateway + Lambda + DynamoDBを使う
AWSでのサーバレス構築を考えた時に最も無難でポピュラーな構成(悪く言えばあまり面白みのない)として挙げられる、
の構築を、SAM(Serverless Application Model) で行います。
書くこと
- SAM CLIでプロジェクトの作成
- SAMプロジェクトのデプロイ
- SAMプロジェクトを修正してDynamoDBにテーブルを作成
- SAMプロジェクトの更新
SAM CLIでプロジェクトの作成
まずSAM CLIをインストールします。
$ sam --version SAM CLI, version 0.40.0
インストールができれば早速SAMプロジェクトします。
$ sam init
Which template source would you like to use?
1 - AWS Quick Start Templates
2 - Custom Template Location
Choice: 1
Which runtime would you like to use?
1 - nodejs12.x
2 - python3.8
3 - ruby2.5
4 - go1.x
5 - java11
6 - dotnetcore2.1
7 - nodejs10.x
8 - python3.7
9 - python3.6
10 - python2.7
11 - java8
12 - dotnetcore2.0
13 - dotnetcore1.0
Runtime: 1
Project name [sam-app]: sample
Cloning app templates from https://github.com/awslabs/aws-sam-cli-app-templates.git
-----------------------
Generating application:
-----------------------
Name: sample
Runtime: nodejs12.x
Dependency Manager: npm
Application Template: hello-world
Output Directory: .
Next steps can be found in the README file at ./sample/README.md
sam initを実行すると、3点の質問を尋ねられます。
ここでは、
- SAMのテンプレートとして
1 - AWS Quick Start Templates、 - lambdaのランタイムとして
nodejs12.xを選択し、 - プロジェクト名を入力
しています。
そうすると以下の構造のディレクトリが作成されると思います。
. ├── README.md ├── events │ └── event.json ├── hello-world │ ├── app.js │ ├── package.json │ └── tests │ └── unit │ └── test-handler.js └── template.yaml
SAMプロジェクトのデプロイ
何もしていませんが、早速このままデプロイしてみましょう。
まず、デプロイの準備をします。
上記のソースのままではデプロイコマンドsam deployを使うことができないので、一旦以下のコマンドを実行します。
$ sam build
sam buildを実行すると、SAMプロジェクトのトップレベルに.aws-sam/buildが作成され、
その中にhelloWorldFunctionディレクトリとtemplate.yamlが配置されます。
helloWorldFunctionディレクトリはSAMプロジェクトのトップレベルにあるhello-worldのアーティファクト(成果物、生成物)でこいつをAWS Lambdaへデプロイします。
template.yamlはSAMプロジェクトのトップレベルにある同名のtemplate.yamlを整形したものになっています。
このyamlファイルがcloudformationへアップロードされて、サーバレスを構成するリソースたちのスタックが組み立てられます。
ビルドが成功したら以下のコマンドを実行します。
$ sam deploy --guided
すると以下の質問事項に対する応答を求められます。
1. Stack Name // スタック名を入力 2. AWS Region // お好きなAWSリージョン 3. Confirm changes before deploy // デプロイ実行前にデプロイによって変更されるスタックの状態を確認した上で、 // デプロイを実行できるようにするかどうか(yesにしておいて問題ありません) 4. Allow SAM CLI IAM role creation // SAM CLIがIAMロールを作っても良いかどうか(yesにしておいて問題ありません) 5. Save arguments to samconfig.toml // samconfig.tomlを作成し、 // その中にデフォルトのデプロイパラメータを書き込んでおくかどうか(yesにしておいて問題ありません)
そのままデプロイが実行されることになりますが、
先ほどのConfirm changes before deployを有効にしていると、
Deploy this changeset? [y/N]:
と聞かれます。
Cloudformationスタックの変更部分の一覧が表示されるので確認の上yとしてあげると、
デプロイが最後まで実行されます。
デプロイ後、AWSコンソールのLambdaには以下のように関数が追加されているはずです。


API GatewayのDashboardからエンドポイントを確認して、
URLへアクセスすると、
{"message":"hello world"}
と表示されるはずです。
SAMプロジェクトを修正してDynamoDBにテーブルを作成
ここまででhelloWorldFunctionのデプロイとその実行をトリガーするAPI Gatewayのデプロイが成功しました。
ですが、ここではDynamoDBでのデータの読み書きについても触れたいと思います。
まず、hello-worldのSAMテンプレートにあるtemplate.yamlにはDynamoDBリソースが記載されていないので追記する必要があります。
以下をtemplate.yamlのResourcesに追記してください(丁度既存のHelloWorldFunctionの次あたりに)。
# template.yaml PostFunction: Type: AWS::Serverless::Function Properties: CodeUri: post/ Handler: app.lambdaHandler Runtime: nodejs12.x Events: HelloWorld: Type: Api Properties: Path: /post Method: post Role: !GetAtt lambdaFunctionRole.Arn PostItems: Type: AWS::DynamoDB::Table Properties: AttributeDefinitions: - AttributeName: 'partitionKey' AttributeType: 'S' TableName: 'postItems' KeySchema: - AttributeName: 'partitionKey' KeyType: 'HASH' ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1 lambdaFunctionRole: # lambda関数がDynamoDBとCloudWatchにアクセスするためのロール Type: AWS::IAM::Role Properties: RoleName: 'RoleForLambdaFunction' AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: 'FullAccessToDynamoDB' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - dynamodb:* Resource: "*" - PolicyName: 'WriteLimitedAccessToCloudWatch' PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:* Resource: "*"
ここで定義しているリソースは 1. ポストを行うLambda関数 2. ポストされたデータを保管するDynamoDBテーブル 3. Lambda関数にDynamoDBとCloudWatchへのアクセスを許可するロール の三つです。
リソース定義の詳細についてはここでは触れません(DynamoDBのpartitionKeyとかAWS::Serverless::FuncntionのEvents設定とかIAMロールとか)ので、以下参照のこと。
AWS::Serverless::Functionについて AWS::DynamoDB::Tableについて AWS::IAM::Roleについて
上記のPostFunctionリソースでは、CodeUriにpost/を指定しているので、
SAMプロジェクトにトップディレクトリにpostディレクトリを作成し、その中にLambda関数のソースコードを配置します。
中身のapp.jsは例えばこんな感じになります。
postディレクトリ内でyarnを行い、yarn add -D aws-sdkでDynamoDBを使えるようにしておきます。
// sample/post/app.js const AWS = require('aws-sdk') const dynamo = new AWS.DynamoDB.DocumentClient({region: 'us-west-2'}) exports.lambdaHandler = async (event, _, _) => { const requestBody = JSON.parse(event.body) const table = 'postItems' const items = { partitionKey: requestBody.partitionKey, } const params = { TableName: table, Item: items, } try { await dynamo.put(params, (err, data) => { if (err) console.error(err) }).promise() const response = { statusCode: 200, body: JSON.stringify(items) } return response } catch(err) { console.error(err) return err } }
SAM CLIで作成されるAPI Gatewayでは統合リクエストの設定でプロキシ統合がONになっているので、
ややこしいマッピングテンプレートについて知る必要はなく、渡したリクエストの値はハンドラーの引数eventで参照できます。
上記ではevent.bodyをパースして中の値を取り出しています。
SAMプロジェクトの更新
更新したソースコードとtemplate.yamlを再びビルドしてデプロイします。
まず、SAMプロジェクトのトップレベルで以下を実行します。
$ sam build
すると、.aws-sam/build配下にPostFunctionディレクトリが追加されるはずです。
.aws-sam/build/template.yamlも更新されていると思います。
デプロイは初回で使っていた--guidedを省いて、
$ sam deploy
とだけ実行します。
*この時にCAPABILITY_NAMED_IAMを使えというエラーが出ると思いますので、初回デプロイ時に生成されるsamconfig.toml(SAMプロジェクトのトップディレクトリ)に記載されているパラメータcapabilitiesの値をCAPABILITY_NAMED_IAMに書き換えてください。
CloudFormationスタックの更新状態を確認して、
Deploy this changeset? [y/N]: y
と入力します。
デプロイ後にAWSコンソールに入ると、
DynamoDBにテーブルが追加されます。
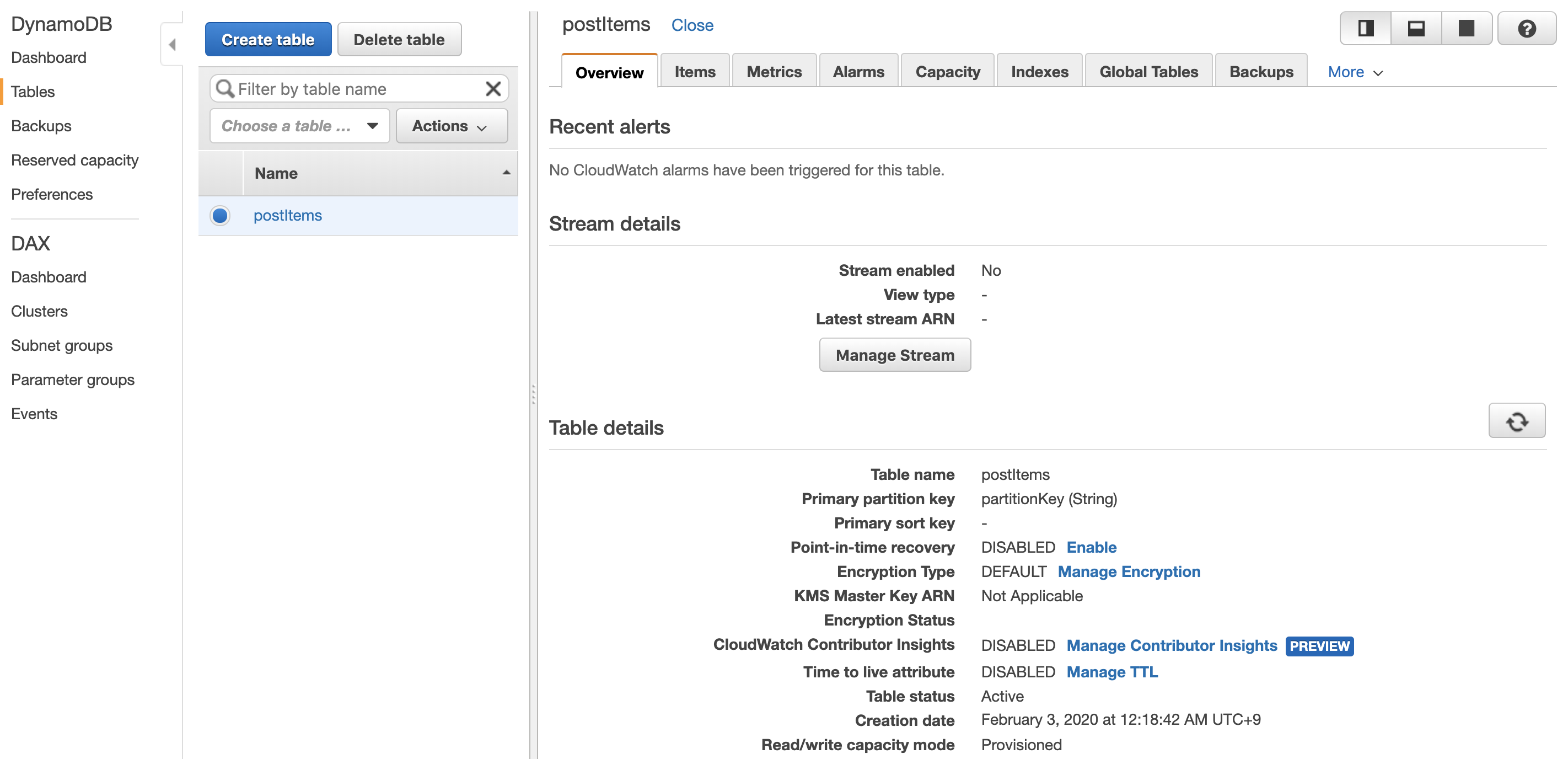
Lambdaにも追加されています。

試しにPOSTしてみる
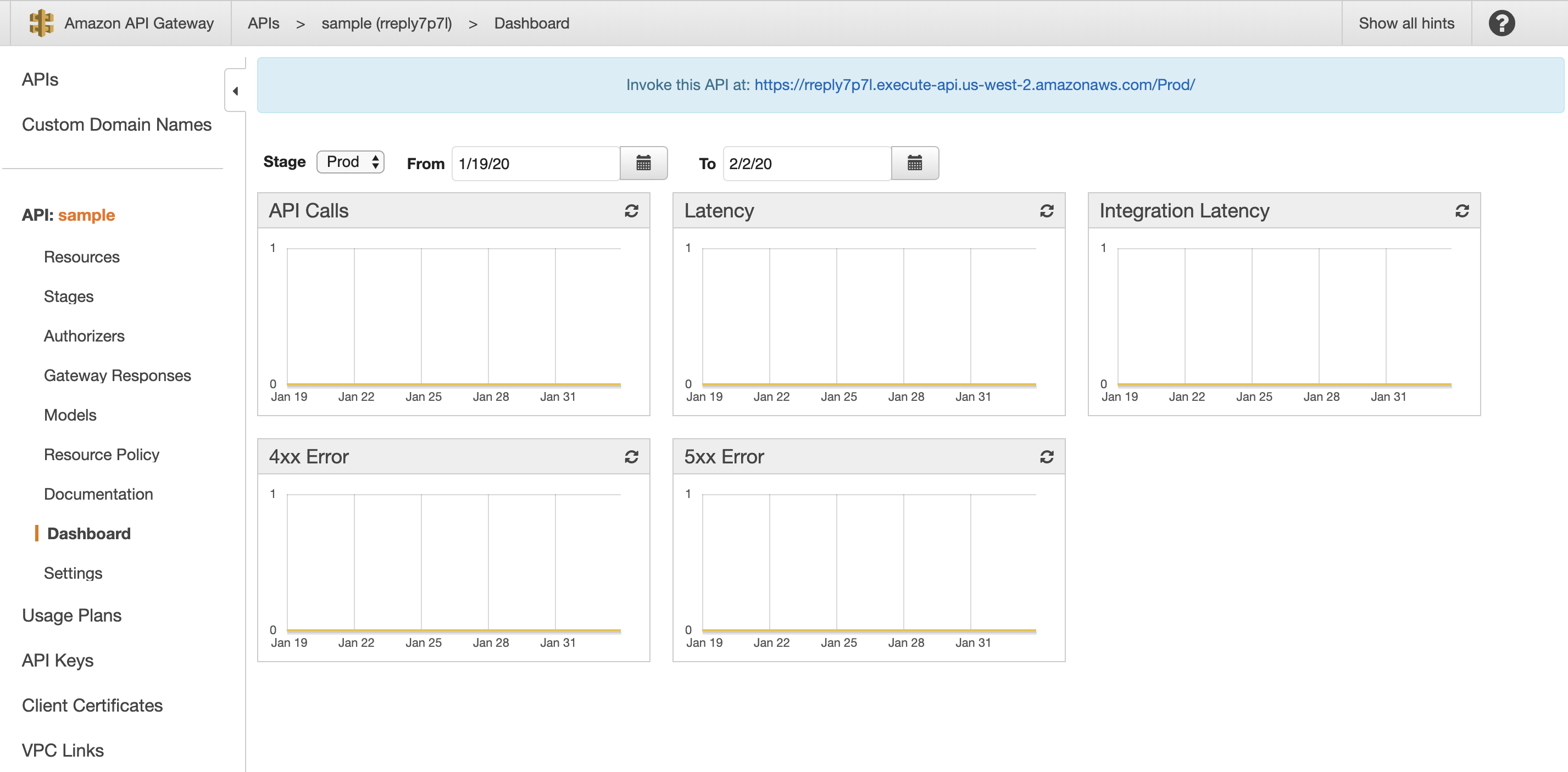
/postへPOSTを行います。
Advanced Rest ClientとかでBodyにpartitionKeyを指定してPOSTします。
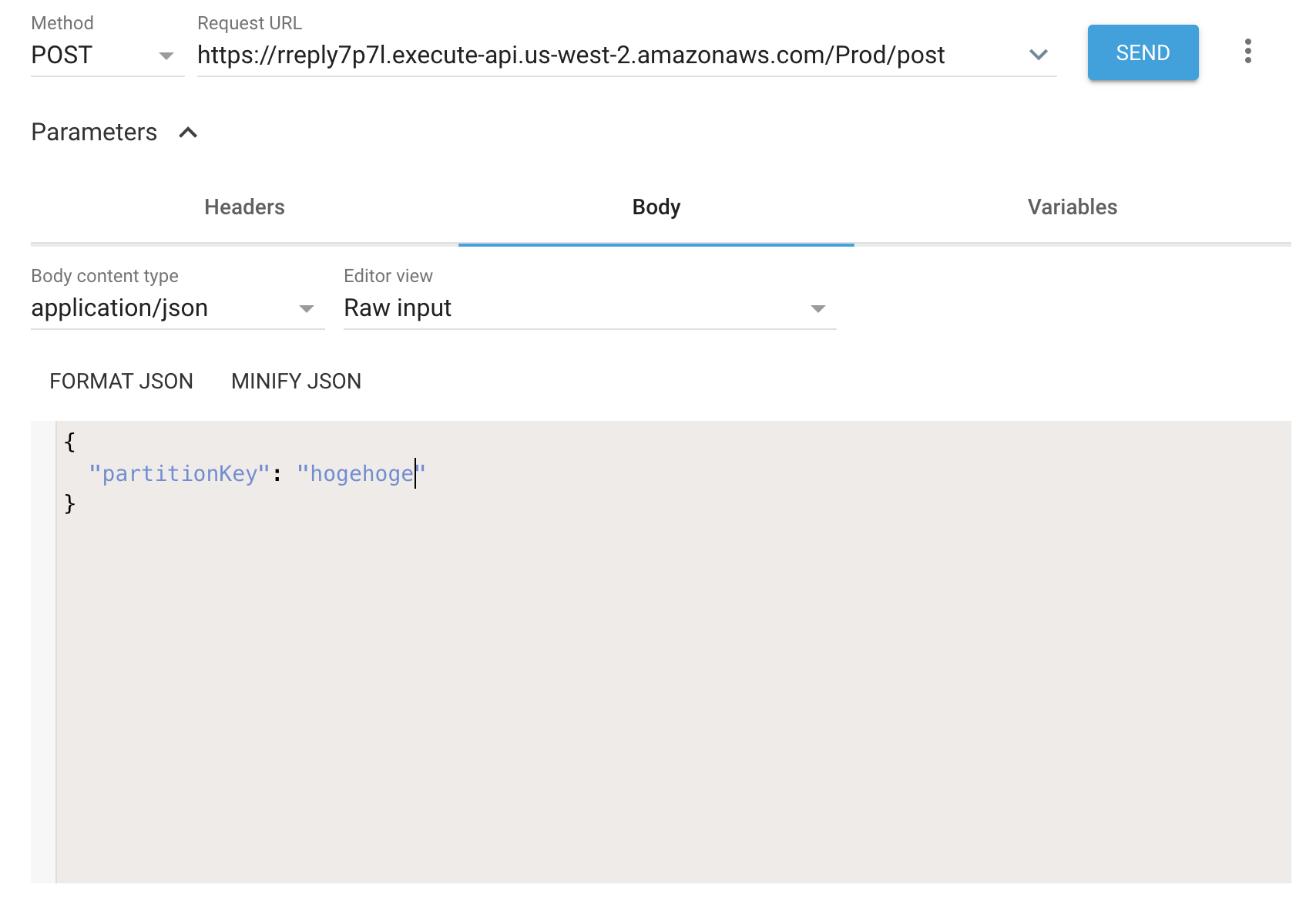
するとPostFunctionのコード内で、リクエストのpartitionKeyをパラメータとして取得してDynamoDBにそのデータを登録します。
こんな感じにデータが入っていると思います。
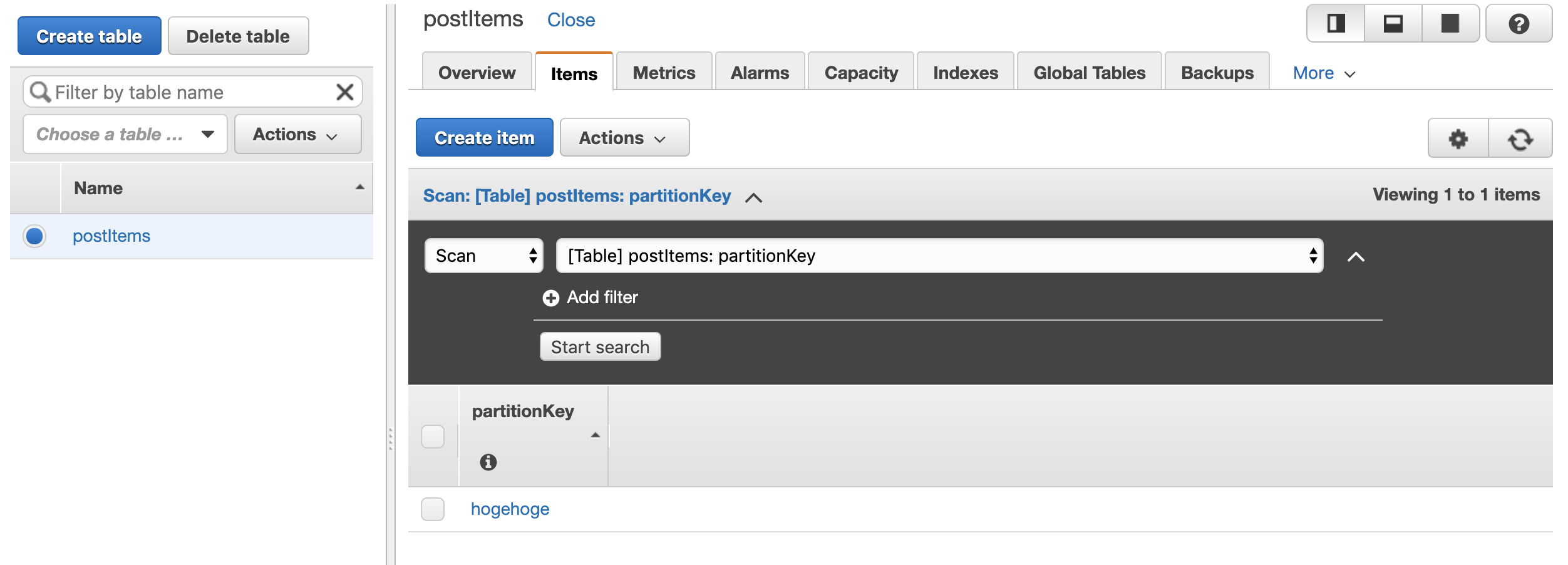
Lambda関数に紐づけているRoleにはCloudWatchへの書き込み権限もあるので、 CloudWatchのログでlambda関数のログストリームを覗くこともできます(以下画像の右側中央部にある「Views logs in CloudWatch」から別タブで開いてみることができる)。

CloudWatchのログストリーム一覧↓
以上でAWS SAMを使ってAPI Gateway + Lambda + DynamoDBをつかったサーバレス環境を構築できました。 他にもいろいろリソースがあるので自分なりにcloudformationのテンプレートを書き換えてみると面白いと思います。
CodePipelineでS3にデプロイしてCloudFrontでコンテンツを配信する
CodeStarでさくさくCI/CD作りもいいのだが、とりあえず一旦はCodeCommitからDeployまでCodePipelineで連携する方法を理解しておこうと思ったので、軽く試してみた。
CloudFrontで配信するところまでやってみる。
やること
- CodePipelineを利用して、CodeCommit, CodeBuildを連携させ、ReactクライアントをS3にアップロードする(デプロイ)。
- S3に配置されたReactクライアントをCloudFrontで配信する。
やる順番
- CodeCommitでリポジトリを作成
- CodeBuildでビルドの設定(テストの設定とかはしない)
- CodePipelineでCommitからDeployまでを一貫して行う(S3へビルドファイルをアップロード)
- CloudFrontでコンテンツを配信(細かい設定はしない)
CodeCommitでリポジトリを作成
AWSコンソールのCodeCommitを開き、リポジトリを作成する。
仮にリポジトリ名testを作成すると以下のような「接続のステップ」が表示される。
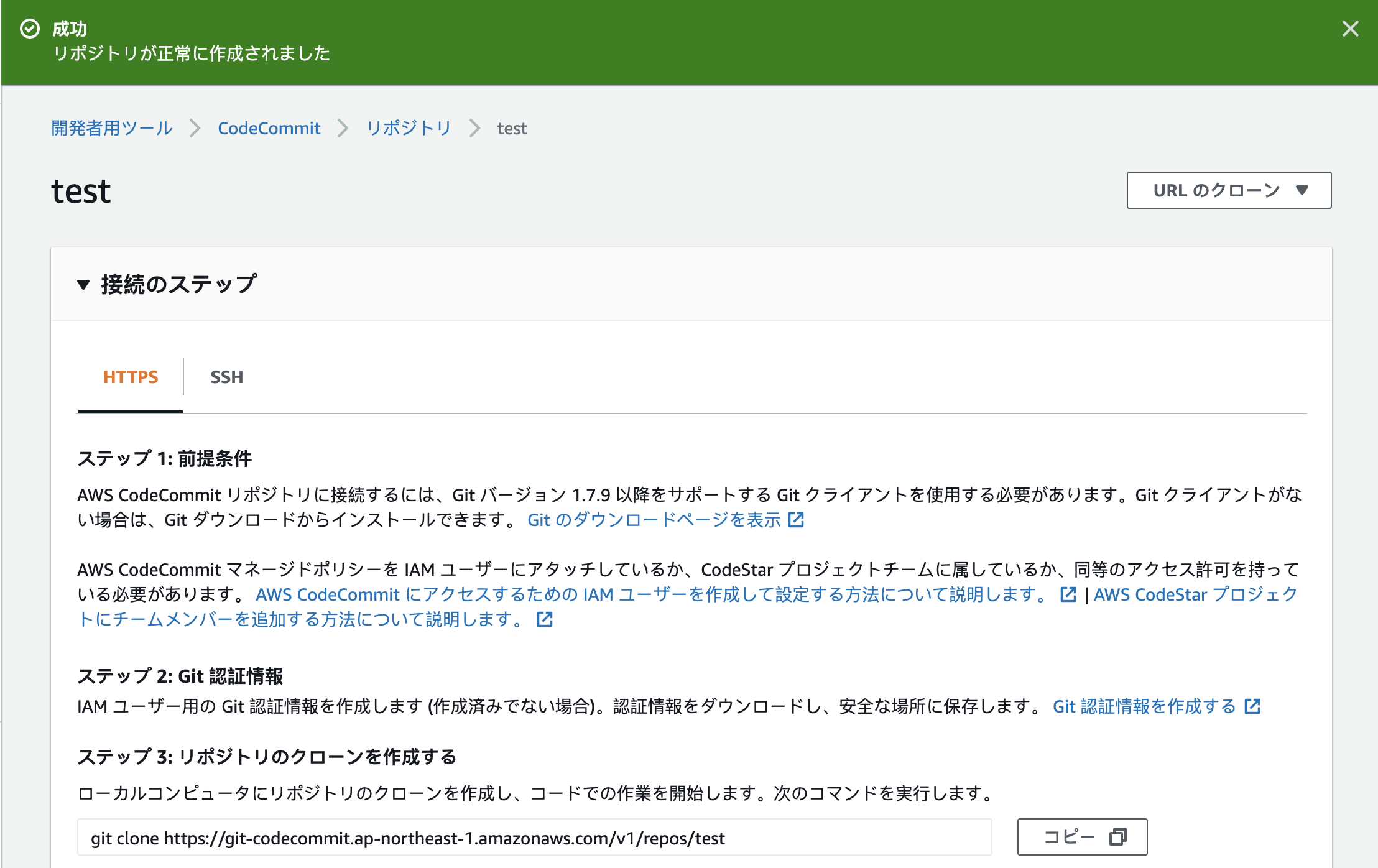
ソースコードをプッシュするには、まずこのリポジトリをクローンする必要がある。 右上の「URLのクローン」から「HTTPSのクローン」を選択すると、URLがコピーされるのでローカルでgit cloneする。
git cloneの際に尋ねられるユーザー名等はIAMの認証情報から取得する。 IAMのアクセス管理>ユーザーからアカウントを選択して、「AWS CodeCommit の HTTPS Git 認証情報」の「認証情報を生成」から証明書をダウンロードする。
中のユーザー名とパスワードを使ってgit cloneできるようになる。
cloneしたディレクトリにソースコードを置いてプッシュすればCodeCommitにソースコードが表示される。
CodeBuildでビルドの設定
AWSコンソールのCodeBuildを開き、ビルドプロジェクトを作成する。
公式の解説ページも参考に。 CodeBuild でビルドプロジェクトを作成する
「ビルドプロジェクトを作成」へ入ると、
- プロジェクトの設定
- 送信元
- 環境
- Buildspec
- アーティファクト
- ログ
の設定項目が目につくが、ここでは「送信元」、「環境」、「Buildspec」のみに触れる。
「アーティファクト」と「ログ」の設定は触れずにビルドプロジェクトを作成する。
CodeBuild 送信元設定
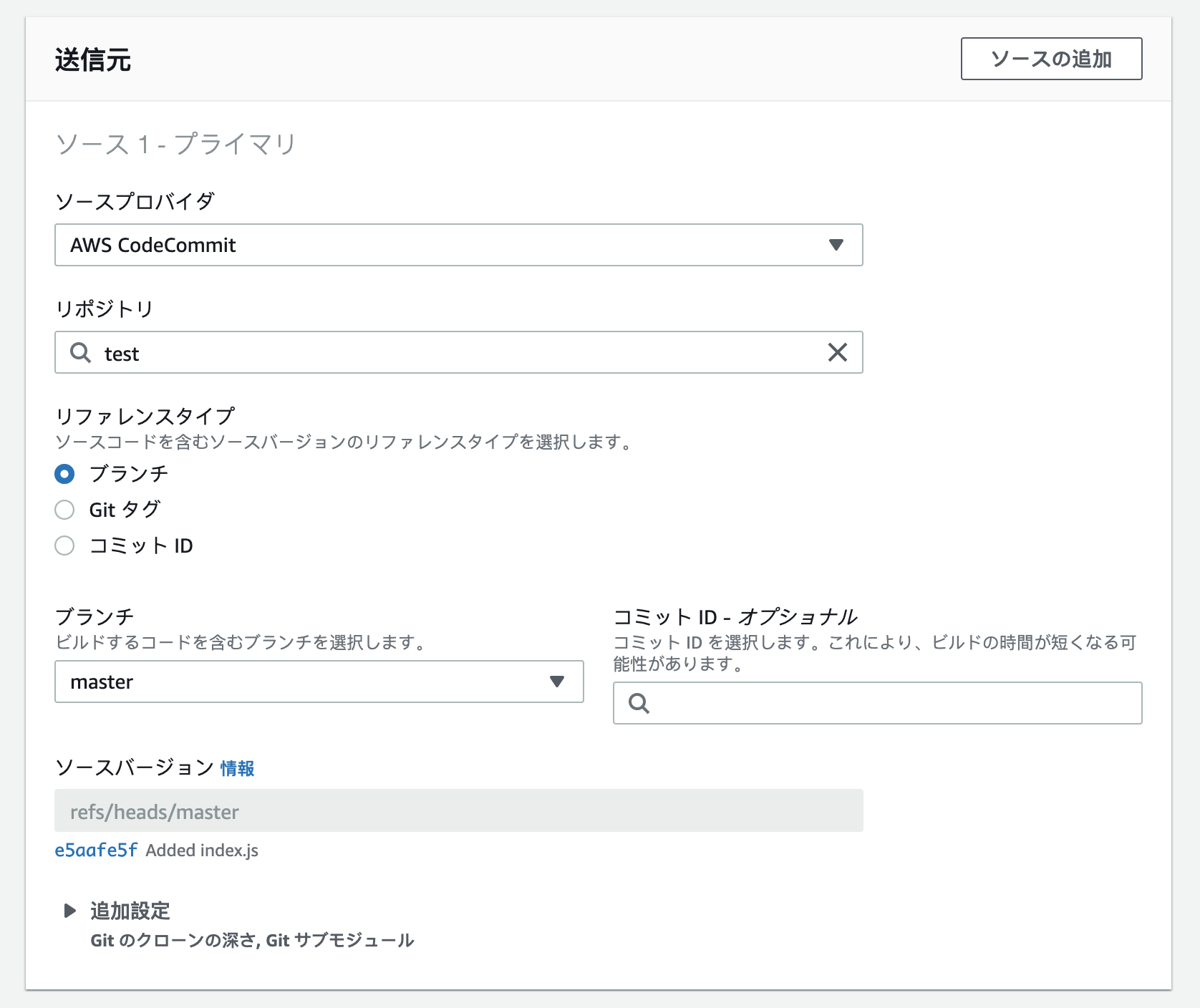
ここで指定するソースプロバイダは、CodeCommitの入力アーティファクトを出力するソースコードを指す。
CodePipeline(CodeCommit, CodeBuild, CodeDeployをCI/CD機能)では入力アーティファクトと出力アーティファクトが各フェイズで受け渡される。 アーティファクトとはそれぞれのフェイズの成果物のことで、CodeCommitの出力アーティファクトはコードそのものであり、CodeBuildはそれを入力アーティファクトとして受け取って、ビルドしたファイルを出力アーティファクトとしてCodeDeployへ渡す。
CodeBuild 環境設定

ビルド環境設定では、ビルドを実行するためにCodeBuildが使用するオペレーティングシステム、プログラミング言語ランタイム、およびツールの組み合わせを設定することができる。
特にこだわりがないのであれば、 OS、ランタイム、イメージ、イメージのバージョン、環境タイプは上記のように設定すればたいして困らないと思う。
サービスロールではCodeBuildの実行に必要なポリシーが組まれたロールが作成される。 すでにある場合は既存のものを使える。
CodeBuild のビルド環境リファレンス CodeBuild に用意されている Docker イメージ
CodeBuild Buildspec設定
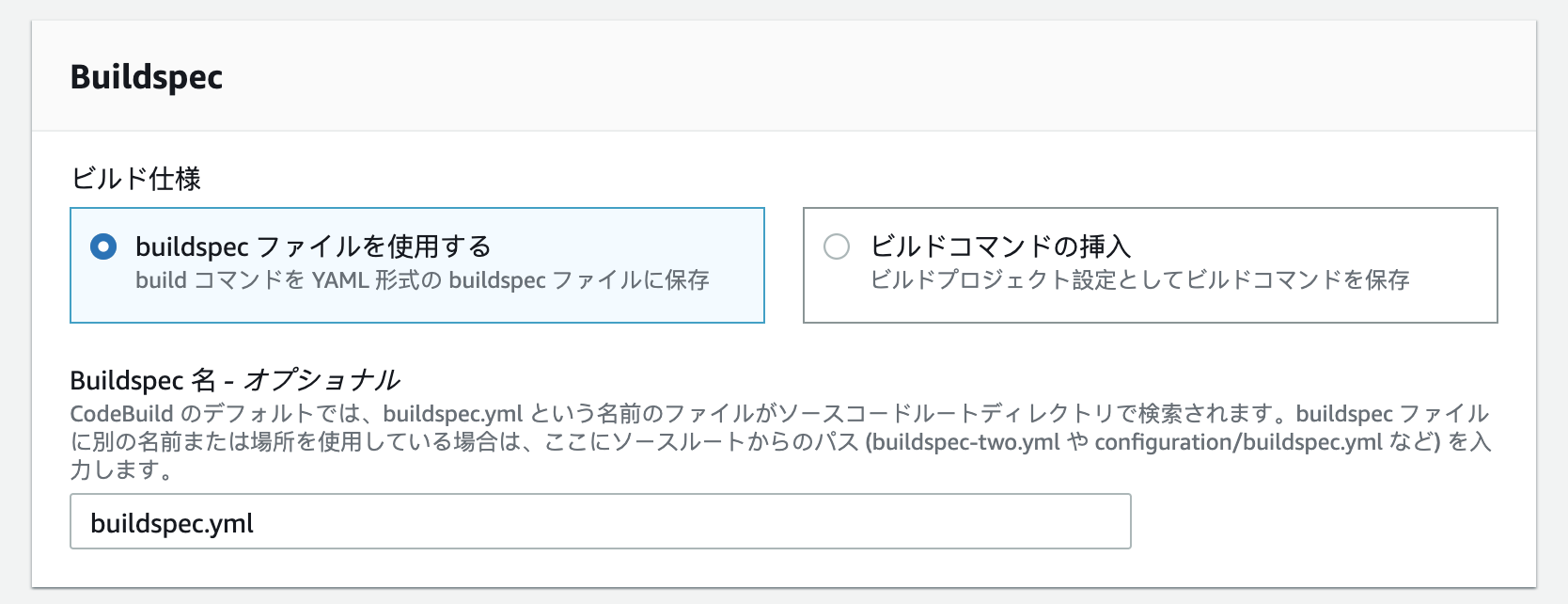
ビルドコマンドの挿入の選択肢もあるが、ここではbuildspecファイルを使ったビルド設定について触れる。 ここまでにCodeBuildがビルドを行うソースコードの設定と、ビルドを行う環境の設定について書いたが、Buildspecではビルドの実行時に実行する細かい処理についての設定を行うことができる。
例えば、reactクライアントをCodeCommitへのプッシュをトリガーとしてビルドしたい場合は、以下のようにディレクトリ内にbuildspec.ymlを配置する。

これがこのリポジトリのルートディレクトリだとすると、Buildspecの項目におけるBuildspec名にはファイルそのものを指定すれば良い。
もしリポジトリ内の特定のディレクトリに存在するBuildspecファイルを指定したい場合は、そのパスを書く(client/buildspec.ymlのように)。
また、このymlファイルの名前がbuildspecである必要はない(clientspec.ymlとかでも良い)。
buildspec.ymlの例 例ではreactクライアントのビルドを念頭に置いているため、runtime-versionsはnodejs10.xを指定しており、 typescriptをインストールしている。
version: 0.2 phases: install: runtime-versions: nodejs: 10 commands: - npm install -g typescript pre_build: # ビルド実行前に実行する処理等の設定 commands: - cd client - npm install build: # ビルド実行処理等の設定 commands: - npm run build # post_build: # commands: # - some command # - some command artifacts: files: - 'client/dist/*' # 出力するビルドファイル discard-paths: yes # 出力するビルドファイルからパスを省く(client/dist/などを省く)
CodePipelineでCommitからDeployまでを一貫して行う
AWSコンソールのCodePipelineを開き、パイプラインを作成する。
パイプライン名とサービスロールを設定すると、
- ソースステージ
- ビルドステージ
- デプロイステージ
の設定に入る。
ソースステージの設定

CodeCommitのリポジトリ名とブランチ名を指定する。 これはビルドステージへの出力アーティファクトとなる。
ビルドステージの設定
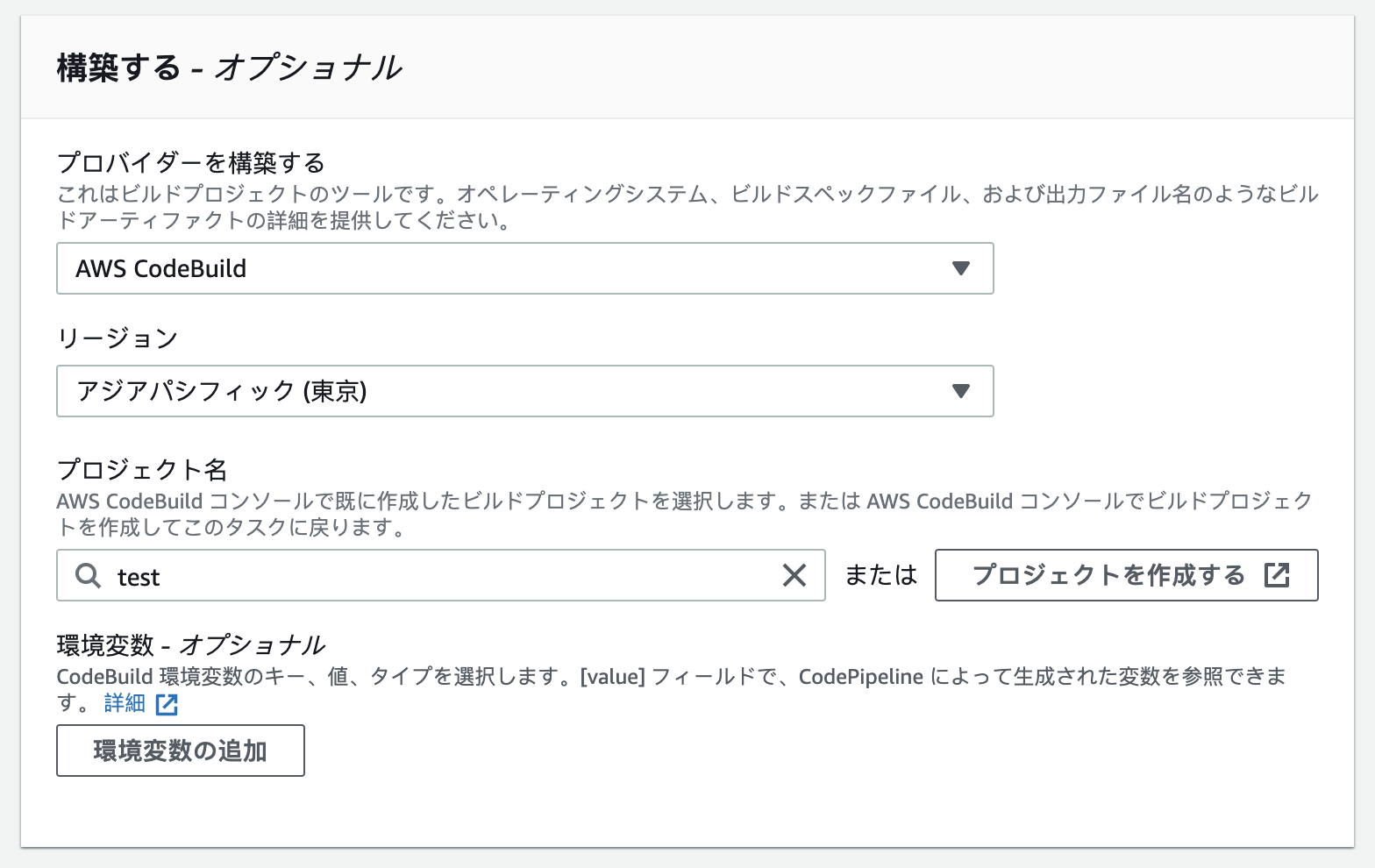
CodeBuildで設定したプロジェクトを指定する。
デプロイステージの設定
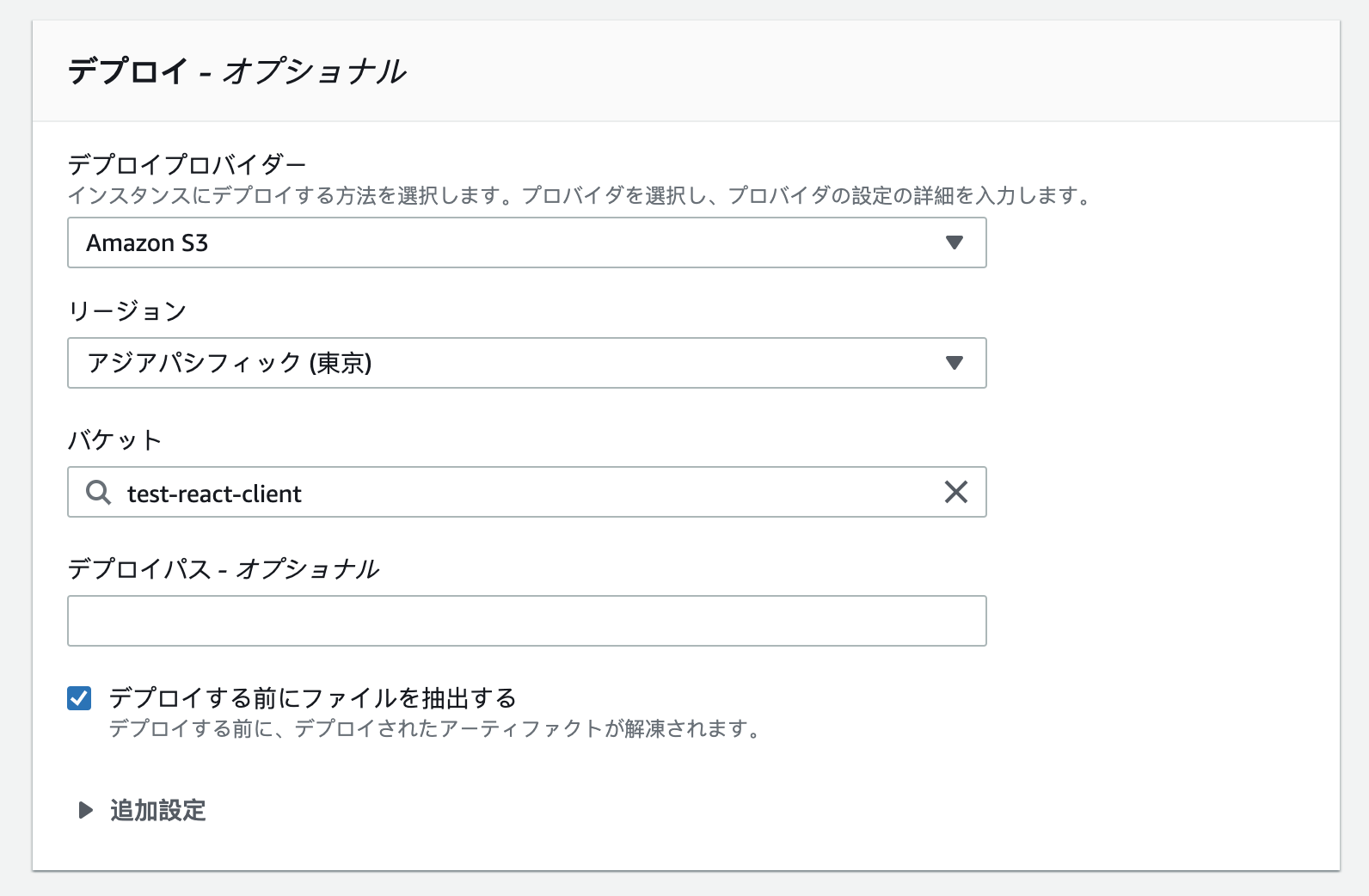
CodeDeployはS3のデプロイに対応していないため、S3デプロイを行うためにはCodePipelineを使う必要がある。
デプロイプロバイダーにS3を指定し、デプロイ先のバケットを選択する。 ここでは「デプロイする前にファイルを抽出する」にチェックを入れている(何もしないとzipがバケットに配置されるが、ここでは解凍された状態で配置したいため。デプロイパスはバケット内に展開されるディレクトリの構成を設定できる)。
全ての設定を終えて確認画面から「パイプラインを作成する」と、パイプライン一覧に新規パイプラインが表示される。 ソースコードに変更を加え、CodeCommitへプッシュすると、自動的にCodeBuildが起動し、S3へのビルドファイルのデプロイが行われる。
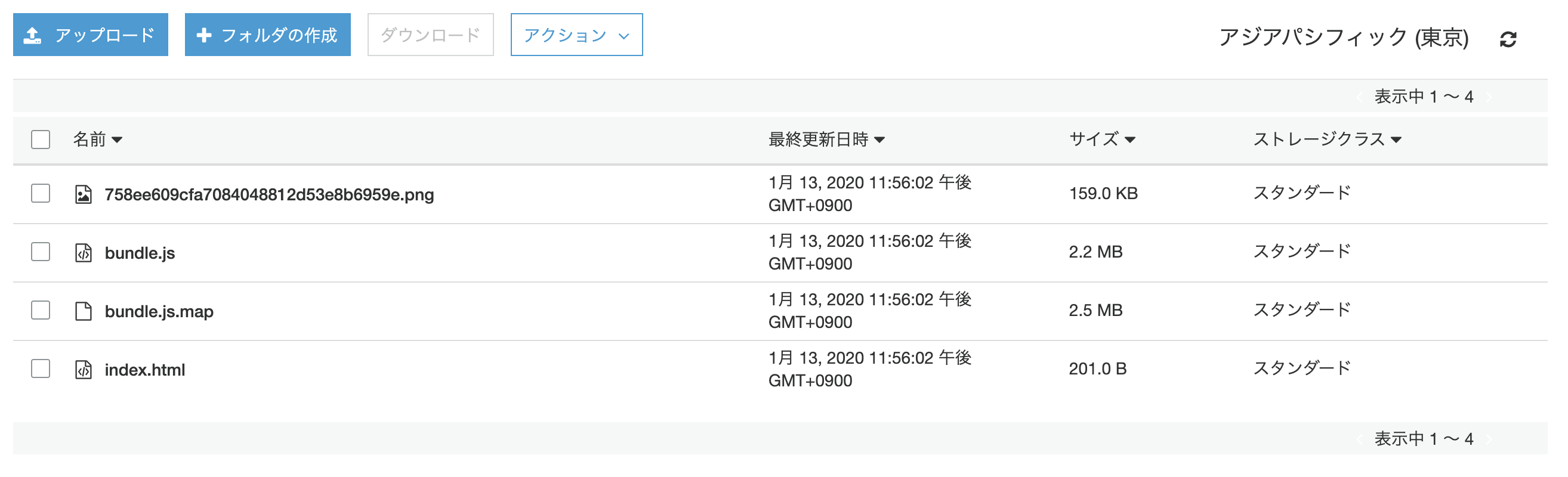
デプロイ設定で指定したバケット内にビルドしたファイルが表示されるはず。
CloudFrontでコンテンツを配信
CloudFrontとはオリジンサーバーが直接アクセスに対応する機会を減らし、キャッシュ化されたエッジロケーションのリソースに対してユーザをルーティングする機能のこと。 Amazon CloudFront とは
AWSコンソールでCloudFrontを開き、CreateDistributionを選択する。
WebのGet Startedからディストリビューションの設定を行う。
Origin Settingでは以下の2点を設定する。
Origin Domain Name CodePipelineでビルドファイルをデプロイしたS3バケットを選択する。
Restrict Bucket Access バケットのリソースへのアクセスを、S3のURLを使わずに常にCloudFrontのURLを利用したアクセスのみに絞りたい場合はこの項目をYesに設定する。
Default Cache Behavior Settingsは飛ばして、 Distribution Settingsでは以下の項目だけを設定する。
- Default Root Object
index.htmlを指定する。 これはバケット内のインデックスドキュメントの設定。 設定しないと${URL}/index.htmlとしてアクセスしなければならない。
Create Distributionをクリックして一覧に表示されるディストリビューションのStatusがDeployedになるまで待つ。

DeployedとなったらDomain Nameに表示されているURLにアクセスしてページが動いているかを確認する。
完。
まとめ
ここまででCodeCommitに新しい変更をコミットしていくと、S3バケットに自動的にビルドファイルがアップロードされるようになる。
厳密なデプロイはそのあとにCloudFrontのディストリビューションのInvalidate(CloudFrontのエッジロケーションのキャッシュを削除して更新されたコンテンツを再配布する)を行ったときに行われる。
InvalidateはCloudFrontのディストリビューションの一覧画面からディストリビューションを選び、Invalidationタブを選択した画面で行える。

Create InvalidationからInvalidateする項目を指定してInvalidateボタンをクリックするだけ。 バケット内の全てのファイルを指定してInvalidateする場合は*(アスタリスク)を指定すれば良い。
今後デプロイの手順としては、
- CodeCommitへコードのプッシュ
- CloudFrontでInvalidateを実行
をするだけでよくなる。
おしまい。
ReactとReduxで複数のReducerを組み合わせてみる
簡単な機能を実装する場合にはreducerは一つだけでも問題はないですが、 機能が増えるとreducerをモノリスにしておくわけにもいかなくなります。
複数のreducerを機能別に分けて使うにはreduxのCombineReducersを使う方法があります。 使い方のまとめとして投稿します。
CombineReducersのインポート例
rootReducerにreducerを注ぎ込む。
このrootReducerの部分はuseSelectorで取得することができるstateになる。
// index.ts import { combineReducers } from 'redux' import { FirstReducer, SecondReducer, } from './reducer' const rootReducer = combineReducers({ first: FirstReducer, second: SecondReducer, }) export default rootReducer
各reducerの例
actionのpayloadは対象のreducerが担当するstateの分だけ用意すれば良い。 CombineReducersがそれらを結合してくれる。
// reducer.ts const initialFirst = { hoge: '', foo: '', } const initialSecond = { bar: '', baz: '', } export const FirstReducer = ( state: typeof initialFirst, action: { type: string, payload: typeof initialFirst } ): typeof initialFirst => { switch(action.type) { case 'HOGE': return { ...action.payload, hoge: action.payload, } case 'FOO': return { ...action.payload, foo: action.payload, } default: return state } } export const SecondReducer = ( state: typeof initialSecond, action: { type: string, payload: typeof initialSecond } ): typeof initialSecond => { switch(action.type) { case 'BAR': return { ...action.payload, bar: action.payload, } case 'BAZ': return { ...action.payload, baz: action.payload, } default: return state } }
API GatewayとLambdaとDynamoDBでサーバーレス環境を構築する
API Gateway + Lambda + DynamoDB = Serverless
AWSでサーバーレスを構築するアーキテクチャを考えた時に、もっとも基本的でわかりやすい構成は、API Gateway + Lambda + DynamoDB(ないしはS3)の組み合わせだと思います。
このエントリーで触れること
AWS SAMには触れないです。
Lambdaで関数を作る
Lambdaで関数を作ってデプロイするのは非常に簡単な作業です。
ランタイムはnode.jsを使います。
関数を作成する方法としては、 1. AWSコンソール上で関数を作成する 2. ローカルで関数を作成してzip化し、Lambdaにアップロードする 3. ローカルで関数を作成してzip化し、S3にアップロードした後に、Lambdaからそれを呼ぶ 4. ローカルで関数を作成してzip化し、cliでデプロイする の4種類の方法があり、もっとも簡便に作るのであれば1で事足ります。
しかし、もっと込み入った内容のロジックが必要なのであれば、2,3,4の方法を選びます。
たとえば、node_modulesを入れてyarnでインストールしてきたライブラリを使いたいとか、lambda上ではできないけどローカルでは用意できるようなものを設定したい時には、2,3,4の方法でデプロイした方が良さそうです。
ここでは1と2,3,4の関数作成方法に分けて簡単に関数を作ってみます。
AWSコンソール上で関数を作成
AWS Lambdaのページからサイドペインの「関数」を選択すると、関数が一覧で表示されます。 この一覧のヘッダー部分に以下のように関数の作成ボタンがあります。

ボタンクリック後の設定では、
- 一から作成(選択)
- 関数名(入力)
- ランタイム(ここではnode.js10.x) (選択)
- 基本的なLambdaアクセス宣言で新しいロールを作成(選択)
「関数の作成」からLambda関数を作成します。
すると、作成した関数の詳細ページへ飛び、関数のコードを編集することができます。
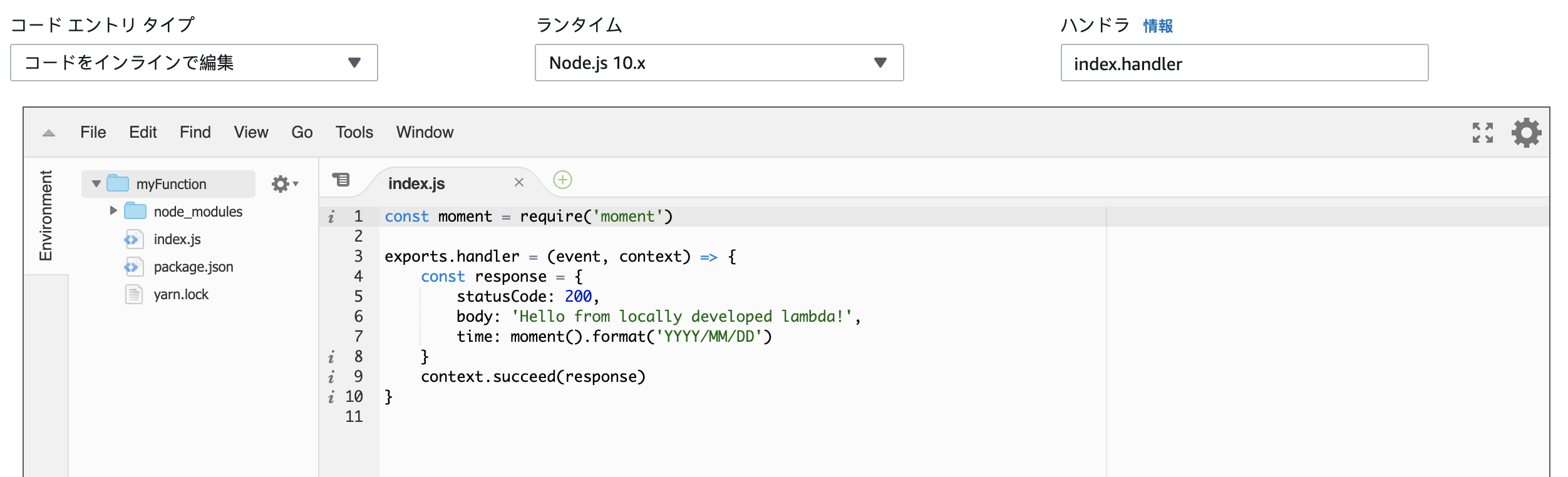
デフォルトのコードでは、'Hello from Lambda!'の文字列がstatusCode200で返ってくるようになっています。 ここでrequestを受け取って処理するなどを行うためには、この後説明するAPI Gatewayの設定を行う必要があります。
ローカルで関数を作成してLambdaにアップロード
$ mkdir myFunction | cd myFunction $ yarn $ yarn add moment $ vim index.js
index.jsの中身は適当にこんな感じで:point_down_tone2:

コードが書けたらnode_modulesと同じレベルのディレクトリ内でzipコマンドを実行します。
$ tree . ├── index.js ├── node_modules // 以下省略 ├── package.json └── yarn.lock $ zip myFunction . -r $ ls index.js myFunction.zip node_modules package.json yarn.lock
解凍した時に上記の内容を含んだmyFunctionディレクトリがトップレベルになる必要があるのでzipコマンドには-rオプション(recurse into directory)をつけています。
zipができたらLambdaのコンソールに移動して、以下のコードエントリタイプのドロップダウンから「.zipファイルをアップロード」を選択します。
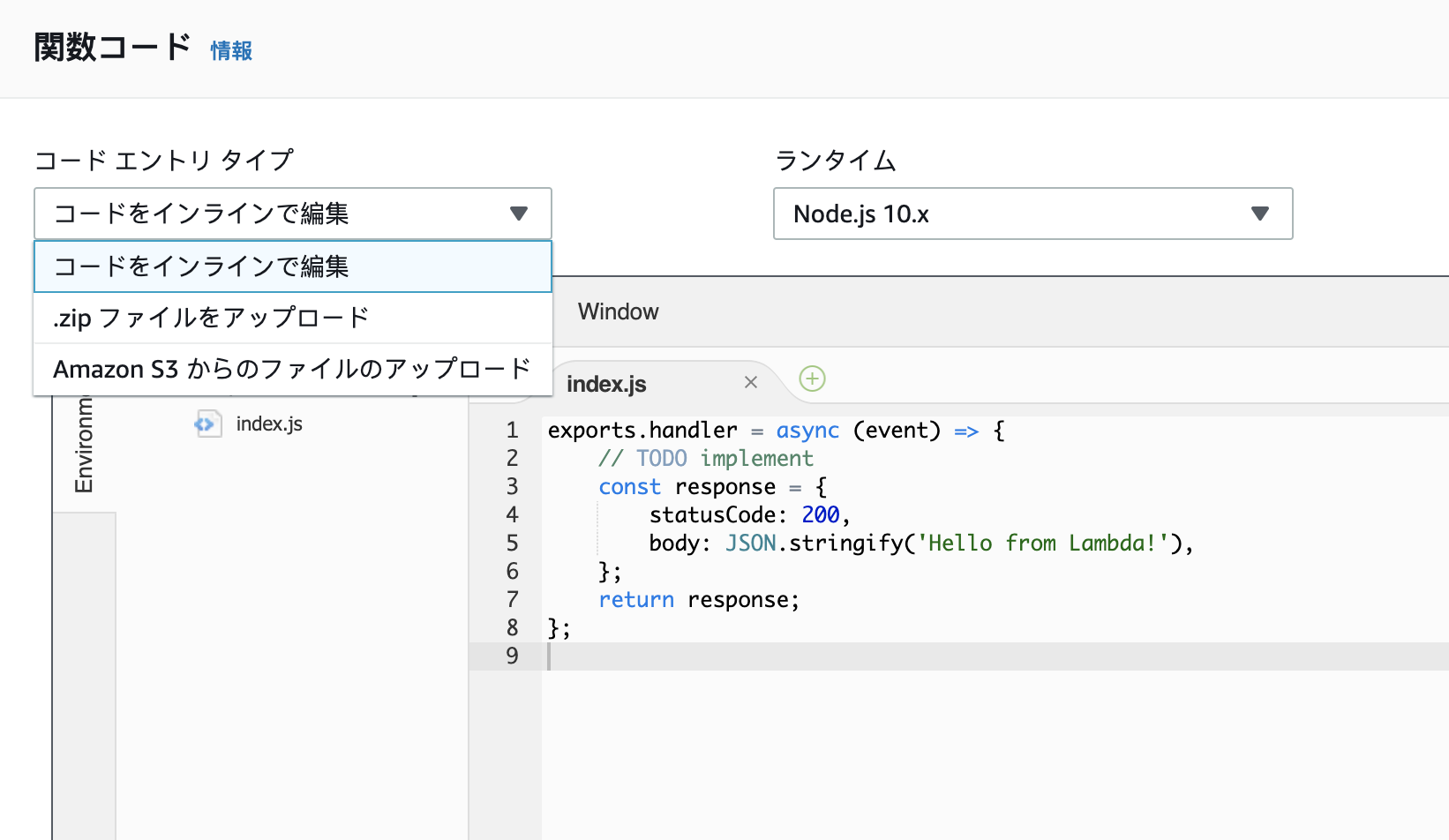
アップロードボタンが出てくるのでそこから上で作成したzipをアップロードしてみましょう。 保存すると、関数コード欄のソースコードがローカルで作成したコードに書き換わります。
インストールしておいたmomentも使えるようになり、エディターのサイドペインにnode_modulesが追加されていると思います。 コンソール上だけだとnode_modulesを利用することができませんが、このようにローカルで作成してからアップロードするとコンソール上でもnode_modulesを扱えるようになります。

ローカルで関数を作成してS3にアップロード
Lambdaに直接zipをアップロードすることもできますが、S3にアップロードしたzipを参照することもできます。 Lambda上に表示される注意書きにもありますが、大きなサイズのzipをアップロードする際にはS3経由でLambdaにデプロイするのが望ましいようです(具体的には10MB以上はS3の利用を検討した方が良いらしいです)。
上記で作成したmyFunction.zipを使いまわします。
$ zip myFunction . -r
でmyFunction.zipを作成したのち、S3コンソールを開きます。
適当な名前のバケットを作成して、その中にmyFunction.zipをアップロードします。

次にLambdaコンソールを開きます。 関数コードの「AmazonS3からのファイルのアップロード」を選択して、S3にアップロードしたzipのオブジェクトURLを入力します。
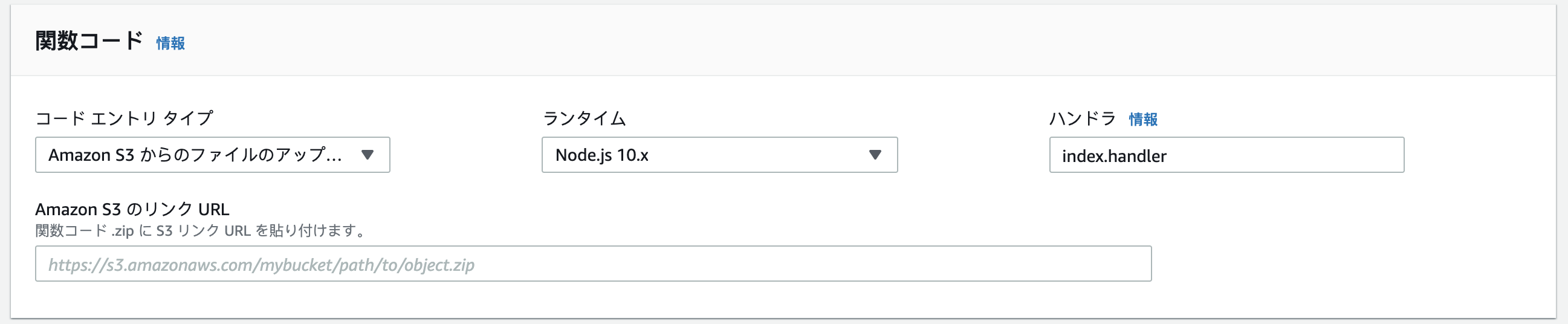
あとは関数を保存するだけです。 テストを実行すると、レスポンスが返ってきます。

ローカルで関数を作成してCLIでデプロイ
CLIで関数を作成する場合は、create-functionを利用します。 https://docs.aws.amazon.com/cli/latest/reference/lambda/create-function.html
create-function --function-name <value> --runtime <value> --role <value> --handler <value> [--code <value>] [--description <value>] [--timeout <value>] [--memory-size <value>] [--publish | --no-publish] [--vpc-config <value>] [--dead-letter-config <value>] [--environment <value>] [--kms-key-arn <value>] [--tracing-config <value>] [--tags <value>] [--layers <value>] [--zip-file <value>] [--cli-input-json <value>] [--generate-cli-skeleton <value>]
また、関数を更新する場合には、update-function-codeかupdate-function-configurationを利用します。 https://docs.aws.amazon.com/cli/latest/reference/lambda/update-function-code.html https://docs.aws.amazon.com/cli/latest/reference/lambda/update-function-configuration.html
update-function-codeはlambda関数のコードを更新するコマンドで、 update-function-configurationはlambda関数の設定(ランタイムや環境変数)を更新するコマンドです。
他のコマンドについてはCLI Command Referenceを参照してください。
さて、デプロイした後はそれだけでは関数は使えませんので、API Gatewayを介して呼び出せるように設定します。
API GatewayからLambda関数を利用する
API Gateway クライアントからの通信を受け付けてLambda関数にリクエストを渡す。 また、そこから受け取ったレスポンスをクライアントに返却する。 (API GatewayはLambda以外にも既存のHTTPエンドポイントやSQSやSNSなどのAWSリソースと連携させることもできます)

① メソッドリクエスト
クエリーのパラメータ等を設定する。
② 統合リクエスト
API Gatewayのリソースが呼び出す対象を設定する(ここではlambda関数となる)。 lambdaへ送るbodyパラメーターのテンプレートを設定する。
③ 統合レスポンス
lambdaから返ってきたレスポンスをAPI Gatewayのレスポンス設定にマッピングする。
④ メソッドレスポンス
API Gatewayがクライアントへ返すステータスコードごとのレスポンスヘッダーやボディを設定する。
API Gatewayでエンドポイントを作る
API Gatewayの「APIの作成」からAPIを作っていきます。 今回はプロトコルをRESTとし、名前はmyAPIとします。

作成されたmyAPIのリソース画面で、「アクション」のドロップダウンをクリックするとアクション一覧が表示されます。 ここでリソースを作成します。
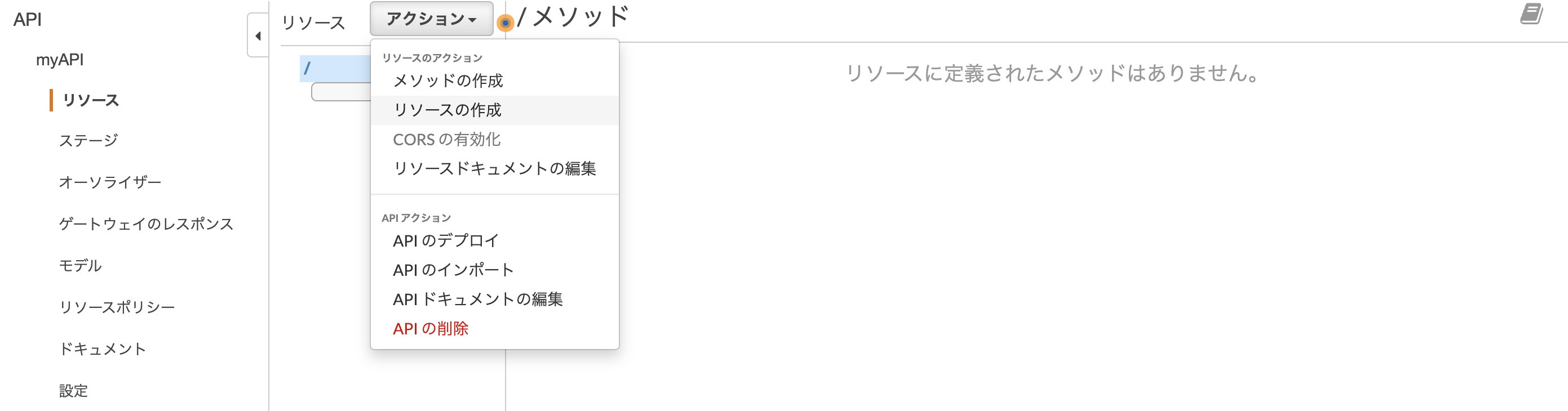
リソース名を入れて「リソースの作成」を行います。
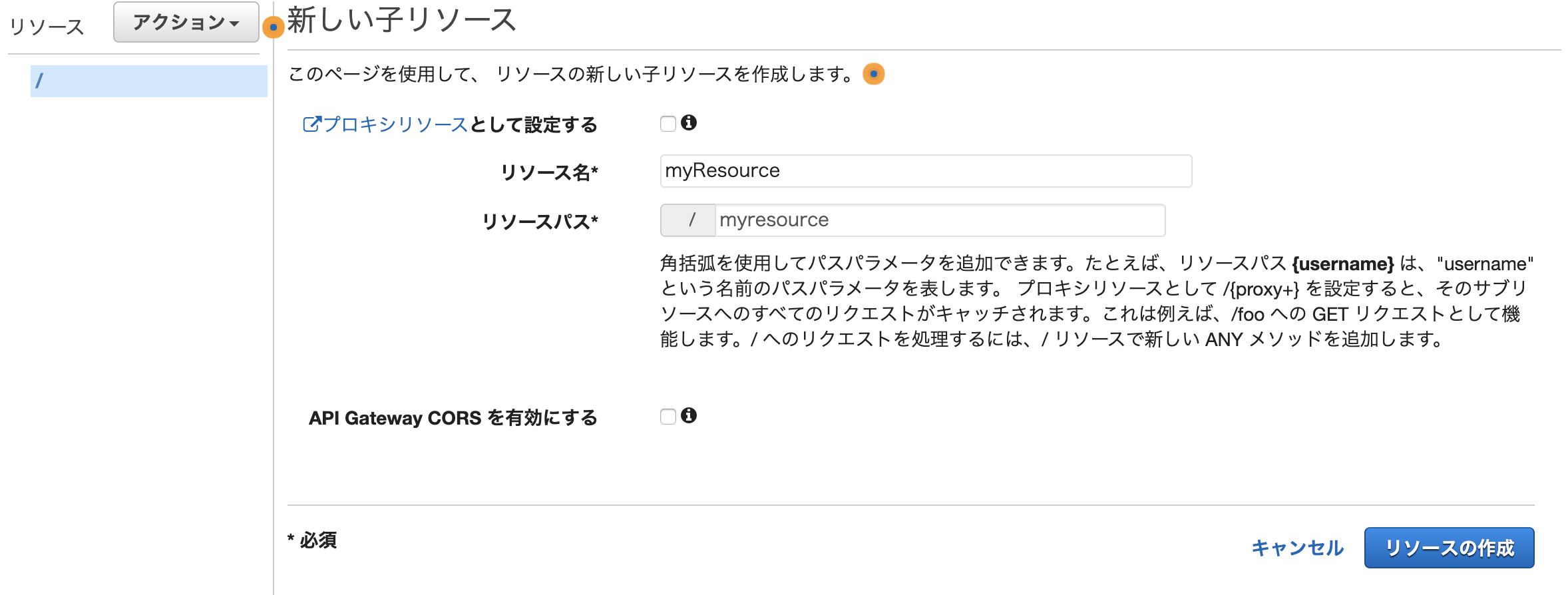
そして、作成したリソースにメソッドを追加していきます。 「アクション」ドロップダウンからメソッドの作成を選択し、メソッドの種類を選択します。 ここではGETを選択してチェックします。
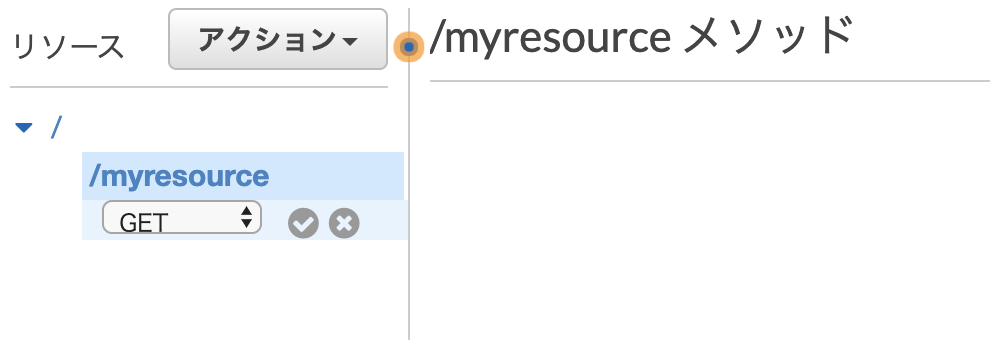
GETメソッドの統合タイプにLambda関数を選択し、 Lambda関数に上記で作成したmyFunction関数を選択します。
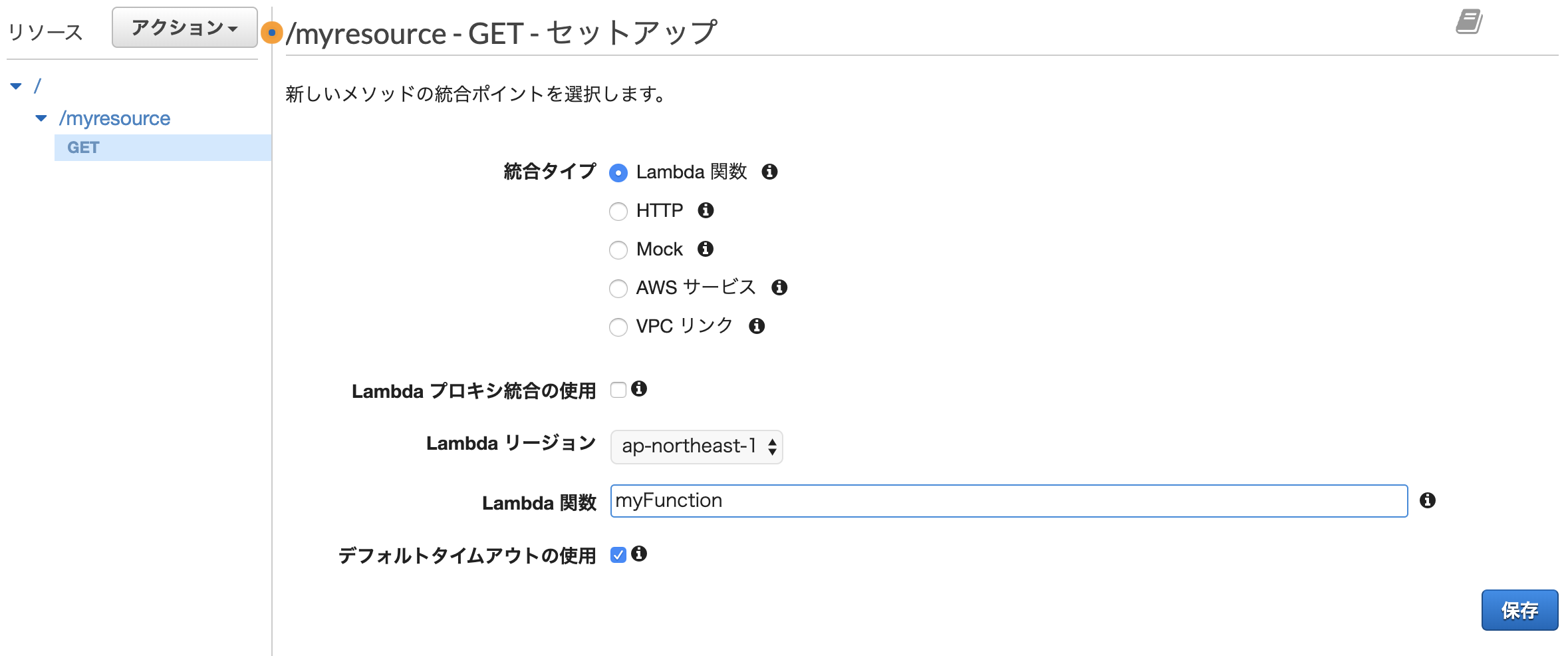
保存すると以下のような画面が表示されます。 ここで前述したメソッドリクエスト、統合リクエスト、統合レスポンス、メソッドレスポンスを設定します。

今回冗長となるのでこれらの細かい説明は省きます。
あとはAPIをデプロイして、作成されるエンドポイント/myresourceにアクセスしてみましょう。 デプロイ時のステージなどは好きなように設定してみてください。

すると、先ほど作成したLambda関数のレスポンスがブラウザに表示されるはずです。

LambdaからDynamoDBに接続する
次はLambdaからDynamoDBの値を取得して、その値をクライアントへ返せるようにします。
DynamoDBにデータを作る
DynamoDBのダッシュボードから「テーブルの作成」をクリックします。
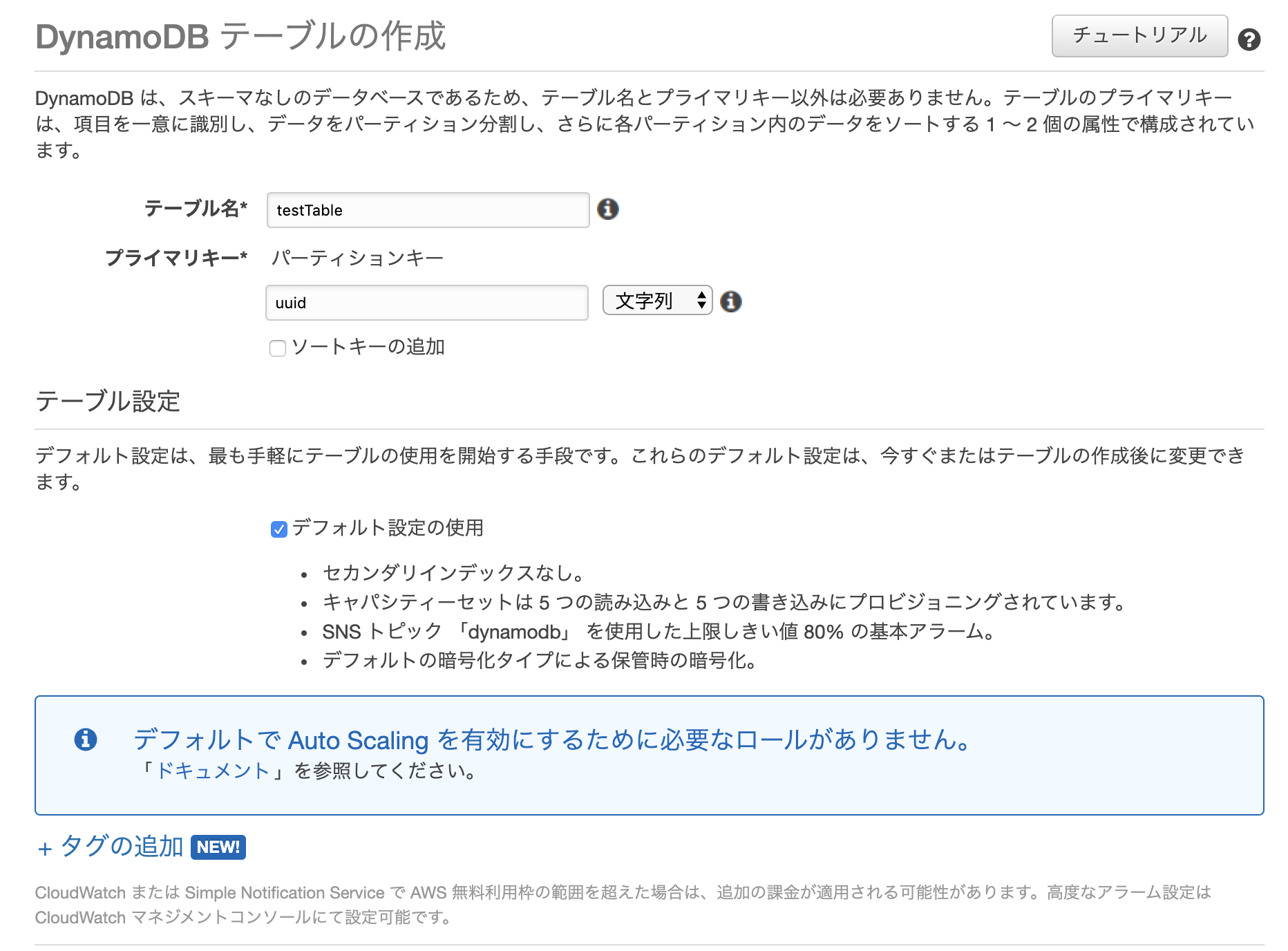
パーティションキー等の設計についてはDynamoDBのベストプラクティスを参考にしてみてください。
作成したテーブルに項目を追加します。 「項目の作成」からパーティションキーの値の他に任意の項目を追加します。
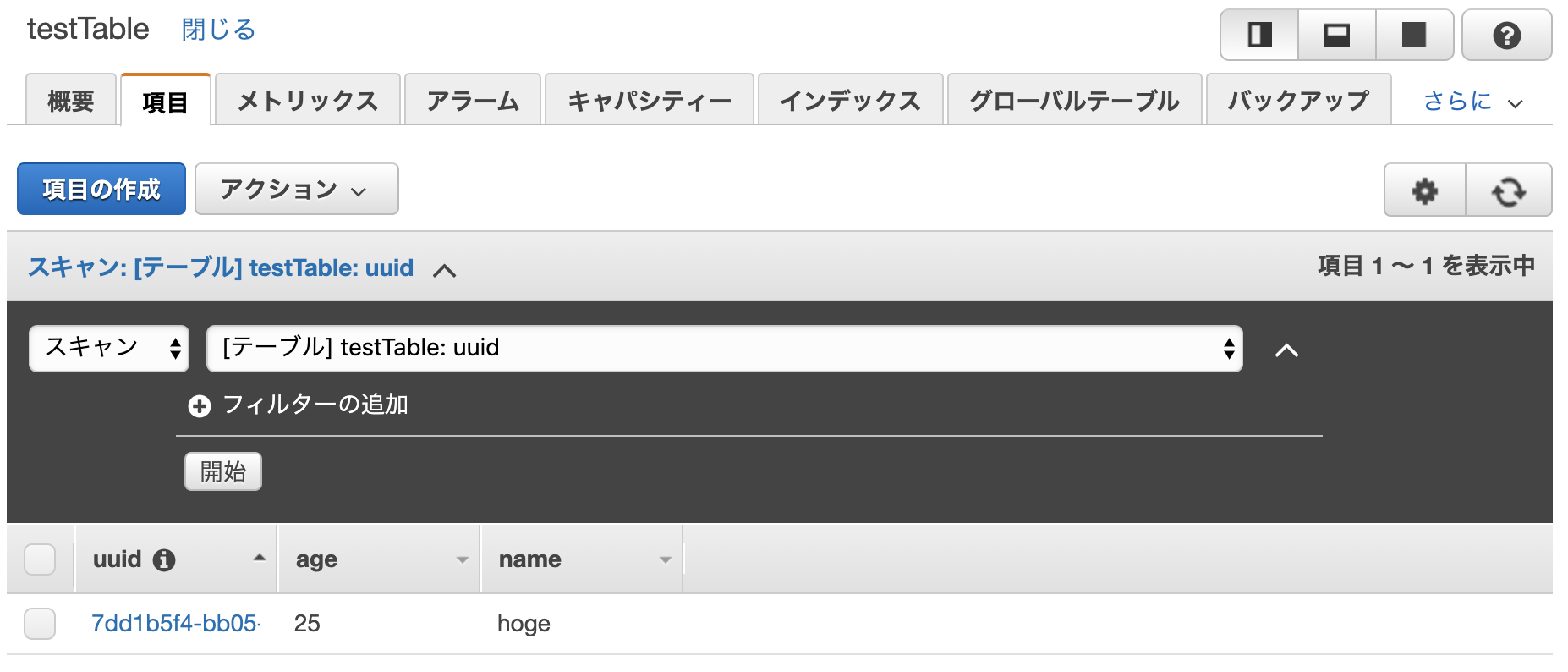
これでデータが用意できたので、このテーブルにLambdaから接続して値を取得できるようにします。
以下のようなjsファイルを用意し、zip化します。
const AWS = require('aws-sdk') const moment = require('moment') const dynamo = new AWS.DynamoDB.DocumentClient({region: 'ap-northeast-1'}) exports.handler = async (event, context) => { const params = { TableName: "testTable", Key:{ uuid: "7dd1b5f4-bb05-4a87-b464-5ddf88254837" } } await dynamo.get(params, (err, data) => { if (err) context.fail(err) context.succeed({ statusCode: 200, body: data, time: moment().format('YYYY/MM/DD') }) }).promise() }
$ tree . ├── index.js ├── node_modules // 以下省略 ├── package.json └── yarn.lock $ zip myFunction . -r $ ls index.js myFunction.zip node_modules package.json yarn.lock
直接LambdaにアップロードでもS3にアップロードしてそれを参照するのでも良いです。 アップロード後に保存してテストを実行してみてください。

こんな感じでレスポンスが返ってきたら成功です。 この関数を紐づけたAPI Gatewayのエンドポイントに接続してみてください。
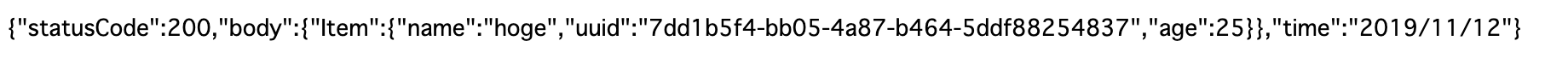
DynamoDBから取得したデータがブラウザに表示されると思います。
もっと応用的に、リクエストを受け取って任意のデータを取得したいような場合には、統合リクエストのマッピングテンプレート等を設定して、Lambdaに渡るeventの中身を定義する必要がありますが、ここでは省きます。
ここまでで以下の項目について触れてきました。
上でやったようにコンソールで色々と操作しましたが、AWS SAMを使えばコマンドラインでサーバーレスを構築する構築することもできます。 ローカルでテストができるのは気が楽ですね:blush:
Gormでトランザクションを実装する
Gormでトランザクションを利用する時の覚書。
DBとの接続およびトランザクションの開始
以下ではTranscation関数を定義し、その中でCRUDの処理を実行するようにしている。 そして、deferでは最終的にTransaction関数から返ってきたerrがnilかどうかを見てロールバックするかコミットするかを判断している。
// main.go func main() { DBMS := "mysql" USER := "root" PASS := "mysql" PROTOCOL := "tcp(localhost:3306)" DBNAME := "sampleDB" CONNECT := USER + ":" + PASS + "@" + PROTOCOL + "/" + DBNAME db, err := gorm.Open(DBMS, CONNECT) if err != nil { panic(err.Error()) } tx := db.Begin() // Transaction関数が存在し、その引数にはトランザクションの情報とCreate処理を盛り込んだ関数を渡す err := Transaction(tx, createFunc) defer func() { if err != nil { tx.Rollback() } else { tx.Commit() } } }
Transaction関数の中身とその引数となるcreateFunc関数
// main.go type CreateFunc func(tx *gorm.DB) error func Transaction( tx *gorm.DB, createFunc CreateFunc, ) error { // create処理を行う err := createFunc(tx) // create処理が失敗したらRollbackさせるためにerrを返す return err } // createFuncではなんらかのCreate処理を行う func createFunc(tx *gorm.DB) error { creature := Creature{Name: "Human", Type: "Mammal"} tx.NewRecord(creature) return tx.Create(&creature).Error // 適宜必要な戻り値があればそれも盛り込んで返すようにする }
Createに加えてupdateやdeleteなどの他の処理も行いたい場合はcreateFuncのように処理を書いて、Transaction関数内に追加していく。
Amazon ECSにGoサーバとMySQLのコンテナをデプロイする
Elasctic Container Service
Dockerコンテナをいい感じにさばいてくれるコンテナオーケストレーションサービスです。
GoのEchoで作ったサーバとMySQLがやり取りする構造を作りたいとき、ECSでどのように実現すれば良いのか調べてみました。 変なことを書いていたらご指摘いただければ幸いです。:bow_tone1:
また、前提として、ここではロードバランサー等を設定して、コンテナが停止した時に自動復帰する部分の設定とかは行なっていません。 飽くまで、タスク実行を行なって、EC2コンテナインスタンスのパブリックDNSにアクセスすると、DBで取得したデータが返ってくるのを確認する、というところまでをかなりざっくりとここに書きます。
macでやっています。
まずDockerComposeでつくってみる
# docker-compose.yml version: "3.1" services: mysql: image: mysql:latest container_name: mysql environment: MYSQL_ROOT_PASSWORD: mysql volumes: # 初期データ設定 - ./initdb.d:/docker-entrypoint-initdb.d # データの永続化設定 - ./mysql/data:/var/lib/mysql ports: - 3306:3306 networks: ecs-network: ipv4_address: 172.30.0.2 server: build: ./golang-server container_name: golang-server volumes: - ./golang-server/src:/server/src ports: - 8000:8000 networks: ecs-network: ipv4_address: 172.30.0.3 networks: ecs-network: driver: bridge ipam: driver: default config: - subnet: 172.30.0.0/24
MySQLのデータベースの初期化を行なって、永続化のためのボリュームを設定しています。 ネットワークもそれぞれ割り振って、golang-serverからmysqlのipv4_addressのport3306に対して接続するようにしています。
docker-compose.ymlがあるディレクトリで、
$ docker-compose build ./ $ docker-compose up -d
を実行してコンテナを立ち上げます。
localhost:8000/userとかでデータを取得します。 (初期値設定でusersテーブルを作成して、go側の実装でそのデータを取りに行っている場合の話)
ECSでデプロイしてみる
MySQLは直接imageから実行するのではなく、Dockerfileを作って以下のように初期化用のデータだけCOPYするようにしました(実行時にdocker-entrypoint-initdb.d以下のsqlファイルが実行されます)。
#Dockerfile FROM mysql:latest # ローカルで作った初期化用sqlファイルが入ったフォルダをあらかじめ仕込んでおく。 # EC2内でのhostとcontainerのvolume設定でもできると思いますが、こっちの方が楽そうと思ったので。 # あと、docker-compose build時点でvolumeが有効になるようにしたかったのもあります(ECRへのプッシュが必要のため)。 COPY ./initdb.d /docker-entrypoint-initdb.d EXPOSE 3306
で、さっきのdocker-compose.ymlのservices.mysqlにあるimage項目をbuildにして、
build: ./mysql
てな感じにして、mysql配下に上の内容のDockerfileを配置します。 で、docker-compose.ymlと同じディレクトリでビルドします。
$ docker-compose build ./
ビルドしたコンテナはこのままではECSで動かすことができないので、ECSで動かすために、AWSのコンテナ置き場に置いてあげます。 そのコンテナ置き場に当たるのが、ECR(Elastic Container Registry)です。
ECRへイメージをプッシュする
ビルドしたコンテナのイメージをECRにプッシュするために、まずはAWSコンソール上でECRに入り、リポジトリを作成します。

上画像の左ペインの一番下の項目Repositoriesをクリックして、「リポジトリの作成」を押します。

次の画面でリポジトリ名を入力して「リポジトリの作成」をクリックすると、リポジトリが作成されます。 以下のようにリポジトリが追加されます。このリポジトリにビルドしたイメージをプッシュするために、このURIの部分を使います。

追加したリポジトリを選択して「プッシュコマンドの表示」クリックします(リポジトリの作成ボタンの横の方にあるボタンです)。 以下の画面が出てくるので、これに従ってコマンドを入力していきます。
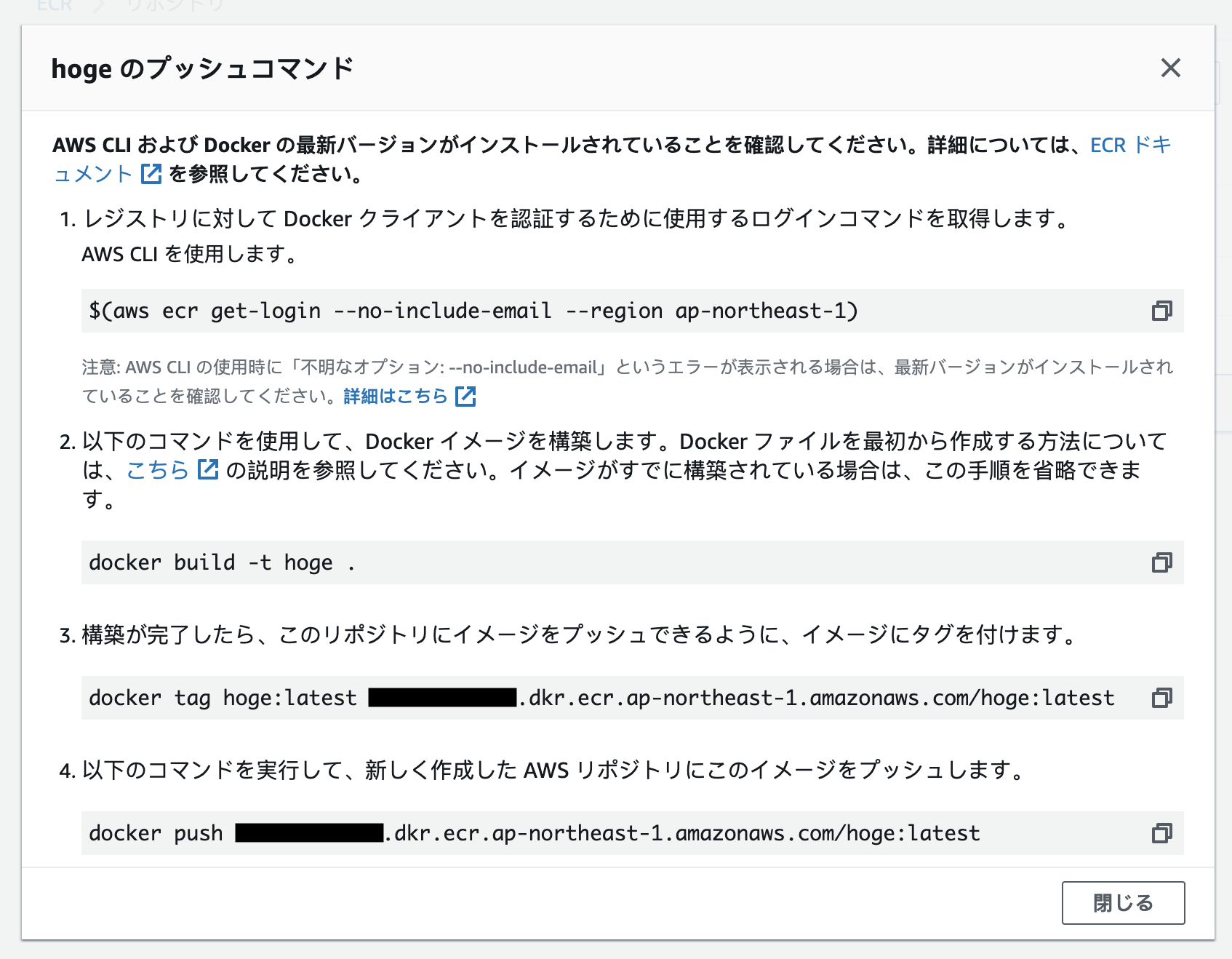
1のカッコの中のコマンドを入力すると、ログインのコマンドが表示されるので、それをまるまるコピーして実行します。
$ aws ecr get-login --no-include-email --region ap-northeast-1 docker login -u AWS -p ####################.....dkr.ecr.ap-northeast-1.amazonaws.com $ docker login -u AWS -p ####################.....dkr.ecr.ap-northeast-1.amazonaws.com
あとはdocker-composeでビルドしたイメージをdocker tagの対象に指定し、最後の引数にさっきリポジトリ作成後に表示されたURIを入力します。 で、最後にタグを指定してECRにイメージをプッシュします。
プッシュが成功すれば、先ほどのECRリポジトリ一覧のリポジトリ名からそのイメージの詳細一覧画面へ遷移してイメージの状態を確認できます。
ECSでコンテナを動かす
ECRにコンテナをプッシュしたので、今度はそれを動かしていきましょう。
ECSではこれらのコンテナをタスクとして扱い、実行していくのですが、 まず、このタスクについての定義を作成する必要があります。 タスク定義はjsonで作成します。
以下のようにタスク定義を設定しました。
# task-def.json { "family": "ecs-demo-app", "volumes": [ { "name": "mysql-data", "host": { "sourcePath": "/mysql" } } ], "containerDefinitions": [ { "environment": [], "name": "golang-server", "image": "ECRのリポジトリのURI", "cpu": 10, "memory": 500, "portMappings": [ { "containerPort": 8000, "hostPort": 80 } ], "entryPoint": [ "sh", "setUpServer.sh" ], "essential": true }, { "name": "mysql", "image": "ECRのリポジトリのURI", "cpu": 10, "memory": 500, "portMappings": [ { "containerPort": 3306, "hostPort": 3306 } ], "environment": [ { "name": "MYSQL_ROOT_PASSWORD", "value": "mysql" } ], "mountPoints": [ { "sourceVolume": "mysql-data", "containerPath": "/var/lib/mysql" } ], "essential": false } ] }
数点の項目に触れます。
family ・・・ タスク名
volumes ・・・ ボリューム名(name)とホスト側のマウント場所(host.sourcePath)を設定できる
containerDefinitions[i].name ・・・ コンテナ名
containerDefinitions[i].image ・・・ コンテナのイメージURI
containerDefinitions[i].portMappings ・・・ コンテナ側のポートとホスト側のポートの対応
containerDefinitions[i].environment ・・・ 環境変数の設定(ここではmysqlに入る時のrootのパスワードだけ)
containerDefinitions[i].entryPoint ・・・ DockerfileのENTRYPOINTと同じ意味。コンテナを立ち上げた時に実行される。CMDとの違いがまだはっきりとわかっていない。。。:sweat_smile:
containerDefinitions[i].mountPoints ・・・ sourceVolumeにvolumesのボリューム名を設定し、そのホスト側のパスにcontainerPathにあるファイル等をマウントすることを宣言する
containerDefinitions[i].essential ・・・ たしかデフォルトでtrueになっている。trueになっているコンテナがこけると、ここで設定した全てのコンテナが停止する。
*外から来たアクセスがgoのサーバーに通じるように、golang-serverのportMappingsのhostPortを80にしています。 *8000:8000でも良いですが、その場合はEC2のセキュリティグループで8000をインバウンドで許可し、最終的にクラスター上で動くEC2のパブリックDNSに:8000をつけてあげれば良いです。
そのほかの項目も含めてタスク定義の設定項目については以下を参考に。 https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task_definition_parameters.html
タスク定義を書いたら、それをECSのタスク定義に登録します。 以下を実行します(ファイル名をtask-def.jsonとしている場合)。
$ aws ecs register-task-definition --cli-input-json file://task-def.json
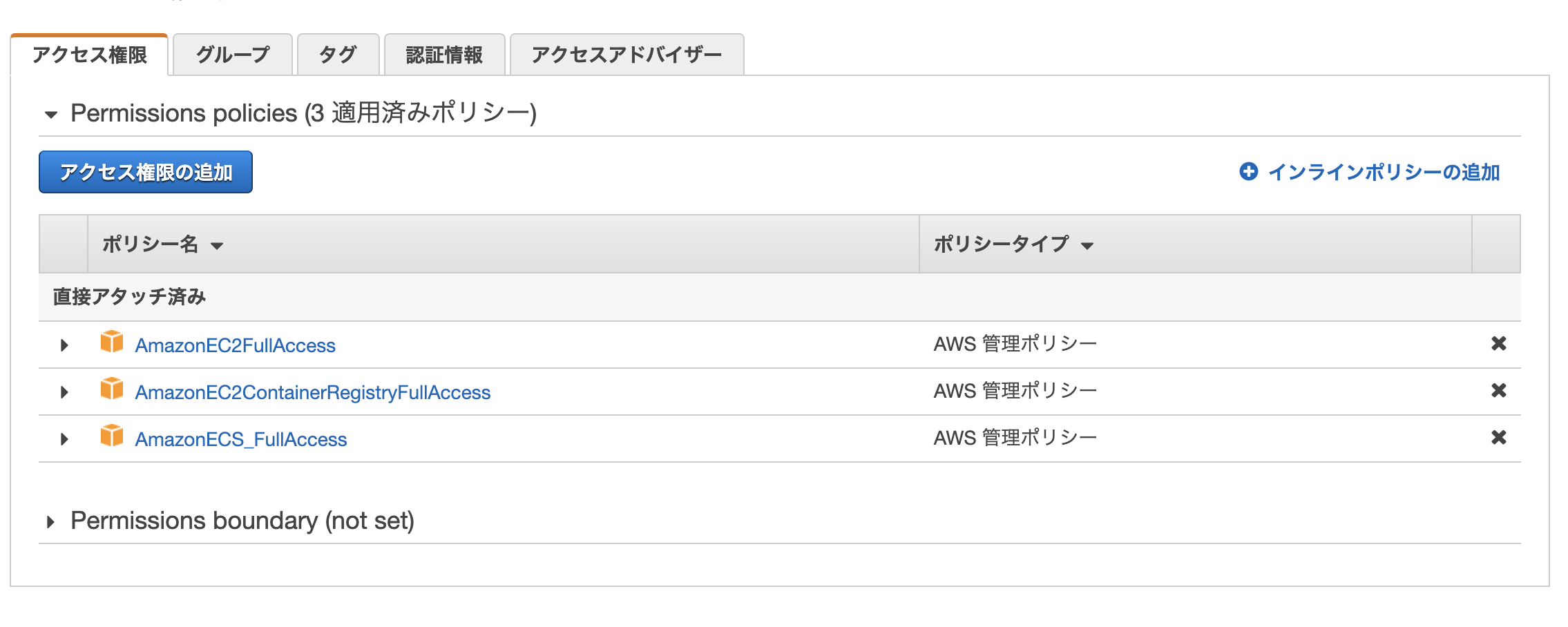
この時、aws configureには、ECRデプロイ用のIAMユーザを設定しておいてください。
*設定方法は以下でいい感じに説明されていたので参考にしてみてください。 https://qiita.com/reflet/items/e4225435fe692663b705
権限設定は以下の感じで良いと思います、ひとまず。
次にECSのクラスターを作成します。 Amazon ECSのクラスターから「クラスターの作成」を選択します。

「EC2 Linux + ネットワーキング」を選択します。

以下のインスタンスの設定だけをいじります。 インスタンスタイプをt2.xlargeに設定し(t2.microでは容量的なエラーが出たので。。。)、 インスタンス数を2つにして(別に1でも問題ないですが。。。)、 キーペアを設定しています。 キーペアはEC2のコンソールから適当に作ってください:key2:

あと、クラスター名も設定して、最下部の作成をクリックします。 クラスターができたら以下の画面みたいになるので、「クラスターの表示」をクリックします。

するとクラスター詳細が出てくるので、この「タスク」タブをクリックします。
「タスク」タブにある「新しいタスクの実行」からさっき作成したタスク(コンテナ)を実行していきましょう。
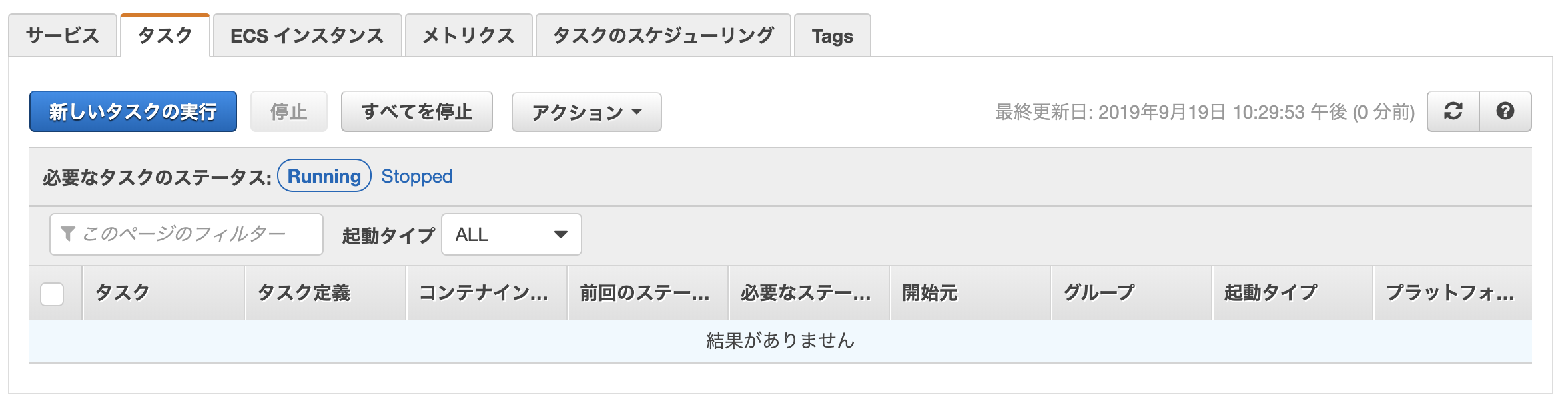
起動タイプはEC2、タスク定義に先ほど登録したタスク定義のリビジョンを選択し、クラスターはそのまま、 タスクの数は一応2にしていますが、1でも良いと思います。 右下の「タスクの実行」をクリックします。
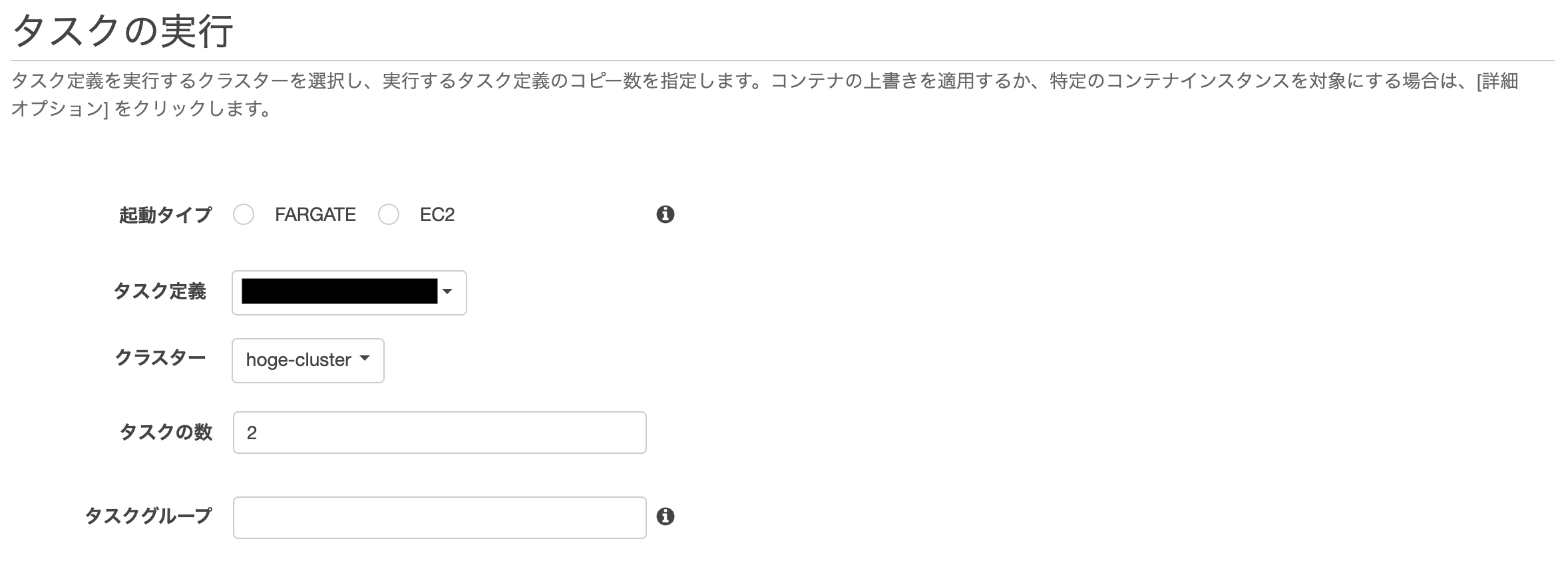
タスク実行が成功すると、以下のようにRUNNINGの状態になります。
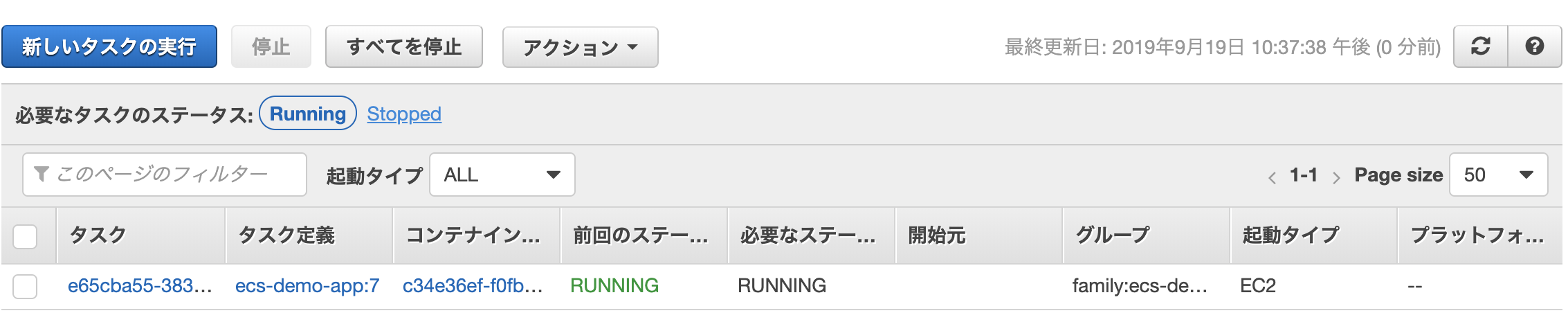
実行中のタスクの数のEC2が起動しているタスクの数だけ表示されていれば良いです。 (さっきタスクを2つ指定したはずなのに1つになっているのはあとで説明します)

失敗したらStoppedから確認できます。 失敗する原因としては単なるコードのエラーや存在しないファイルを参照しているとか、ネットワーク的にうまくいっていないとかがあると思うので、その辺を調べれば良いかなと思っています:sweat_smile:
cloudwatch使えばもっと効率的にログを確認しながらトラブルシューティングできるかもですね、まだやり方わかってません。。。
クラスター上で動いているEC2インスタンスのネットワークの情報は、「ECSインスタンス」タブからインスタンスを選択してみることができます。
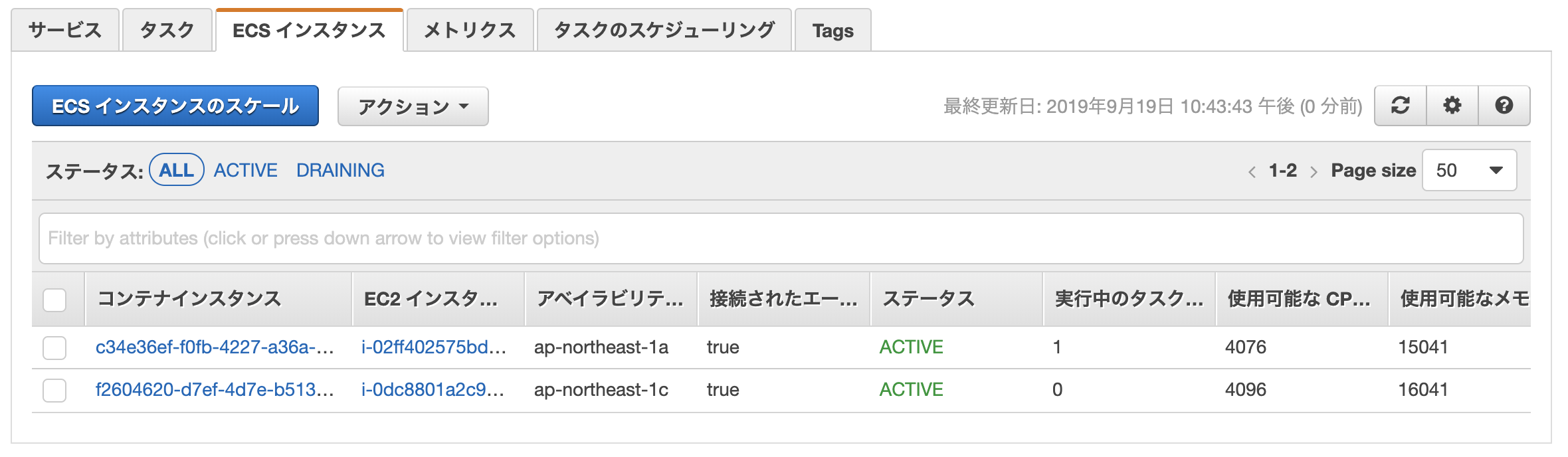
クラスター作成時にインスタンス数を2にしていたので、AZの1aと1cで作られているようです。 1aの方を選ぶと以下の画面が出てきます(テキトーに塗りつぶしていますが笑)。
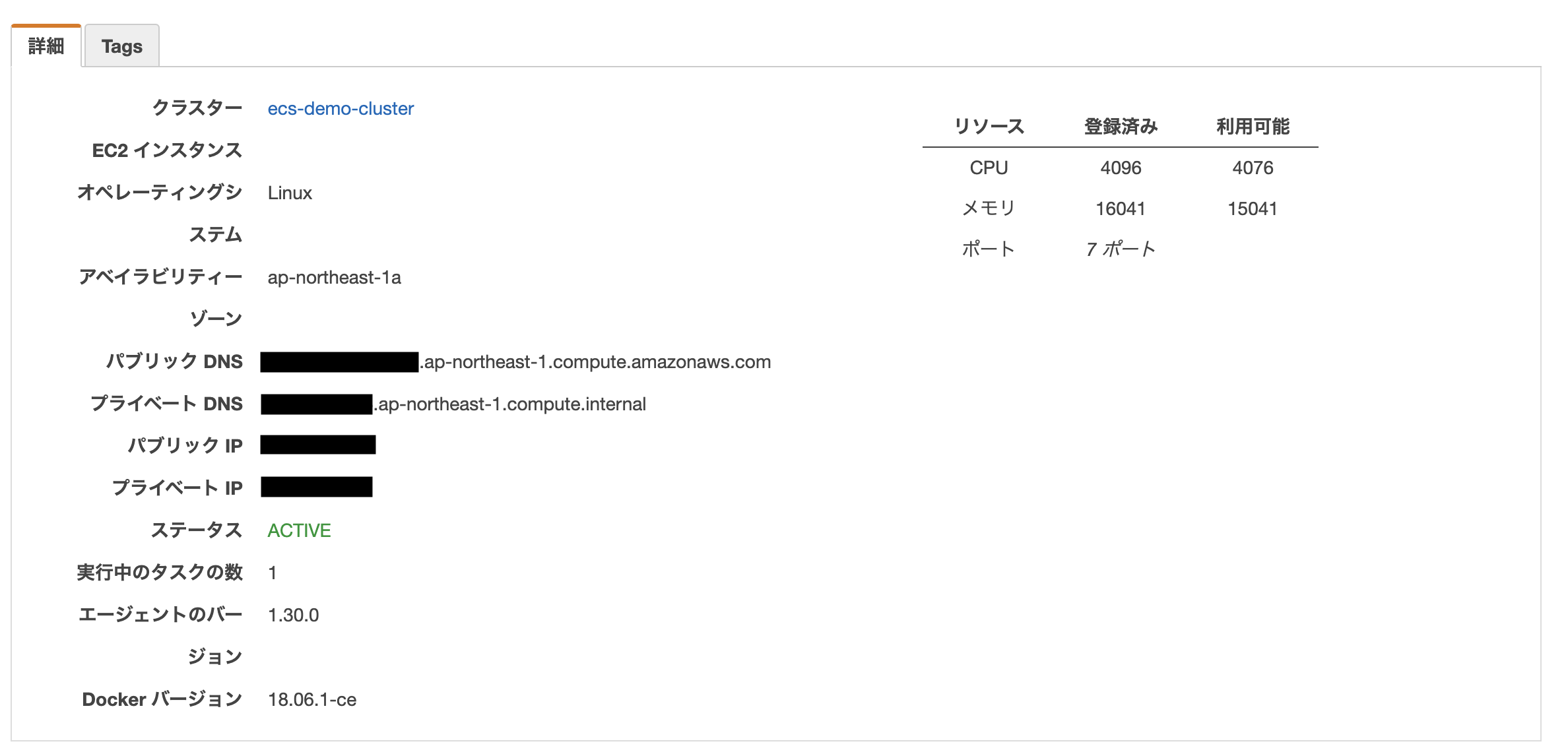
パブリックDNSにアクセスすると、Goのサーバーのアクセスできます(ここではportMappingsが80:8000となっているので)。 /userとかでデータベースから情報が取れていることを確認してみてください(/userとかでデータベースからデータを取れるようにしている場合の話)。
。。。とれなかったら、docker logsとかでログ出したりしてエラー改善してみてください:head_bandage:
コンテナ間の通信について(Goサーバ <=> MySQL)
あと、ここではgormを使って以下のようにmysqlと接続していますが、tcp()の中のIPアドレスは上の画像のインスタンス詳細にある「プライベートIP」を指定してあげるとうまく接続できるようになりました。
// connectionDB.go package database import ( "github.com/jinzhu/gorm" _ "github.com/jinzhu/gorm/dialects/mysql" ) func ConnectionDBWithGorm() *gorm.DB { DBMS := "mysql" USER := "root" PASS := "mysql" // task-def.jsonのenvironmentで設定したMYSQL_ROOT_PATHの値 PROTOCOL := "tcp(ここにプライベートIPを:mysql)" DBNAME := "your database name" CONNECT := USER + ":" + PASS + "@" + PROTOCOL + "/" + DBNAME db, err := gorm.Open(DBMS, CONNECT) if err != nil { panic(err.Error()) } return db }
さらっと書いていますが、mysqlと書いてあげると、mysql(多分task-def.jsonにあるcontainerDefinitionsのname項目を参照していると思われる)が動いているポートを表してくれるようです。
ただ、プライベートIPを上記で設定してあげればよかったのですが、プライベートIPはEC2インスタンス一つにつき一つ存在するものなので、このサーバ側のコードにプライベートIPをハードコーディングすると、そのIPに対応するEC2コンテナ上でしかタスクが動かないことになります。
これが、先ほどタスクが1つだけしか動いていなかったことの原因です。
おそらく、どのインスタンスでもそれぞれのインスタンスのプライベートIPを参照できる環境変数みたいなものがあるとは思いますが(上記で言うところのmysql変数のようなものがあるのだと思っています)、現状わかってないです:pensive: わかる人がいたら教えて欲しいです。。。:pray_tone2: